Vespa 索引结构实现
Table of Contents
上一文大概讲述了 Vespa 与 ElasticSearch 的区别,本文具体展开讲述 Vespa 的索引实现,主要聚焦于数据结构。下篇中会详细讲述如何使用这些数据结构进行检索(TODO)。
倒排索引的底层数据结构
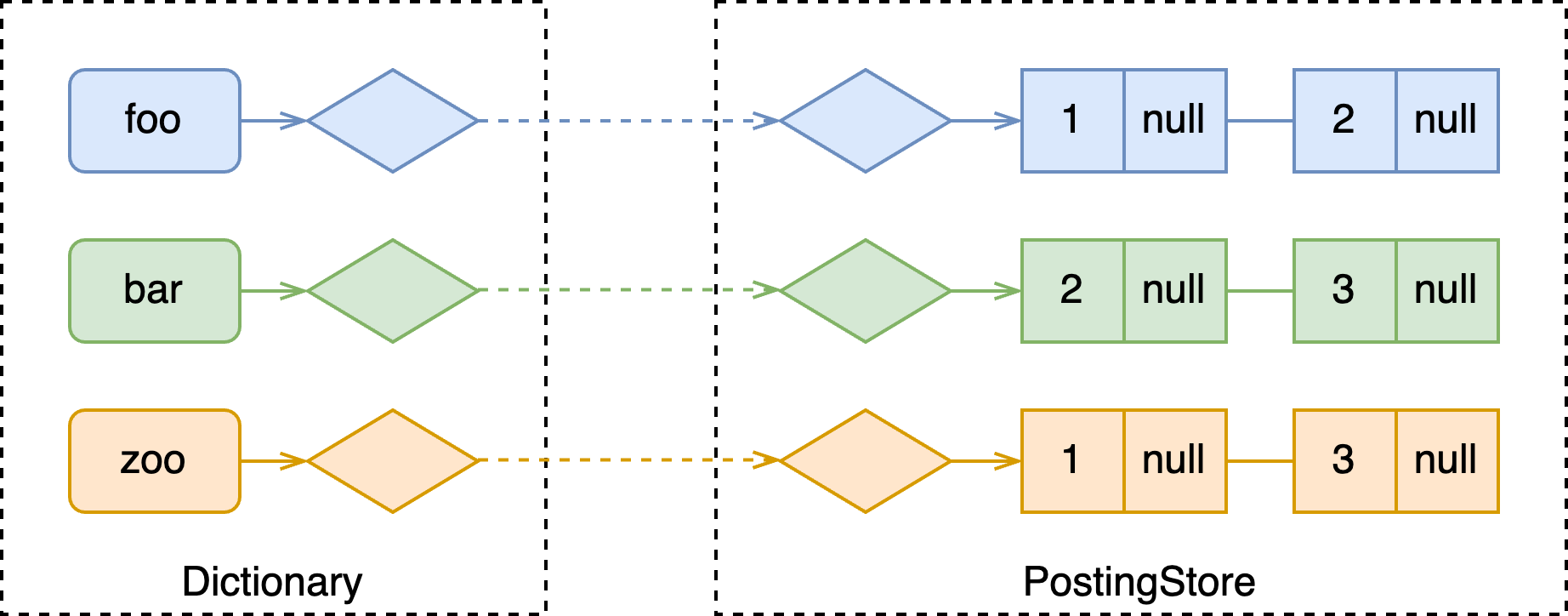
一般来说,倒排索引都包含两部分:词典(dictionary)和倒排表(posting list)。
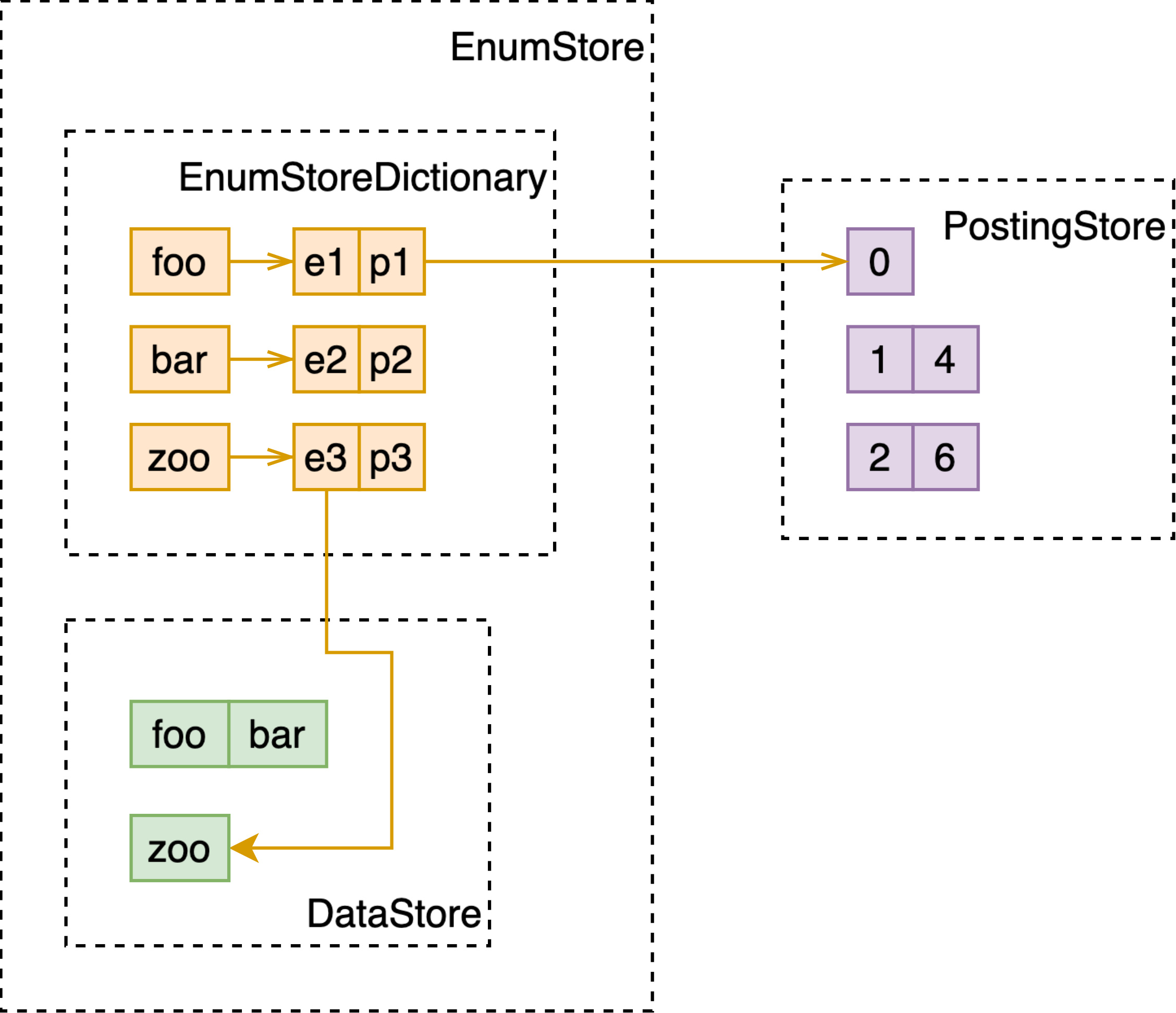
其中词典以 term 为 key,value 为指向其对应倒排表的 id,在 Vespa 中称为 EnumStoreDictionary。
倒排表中也存储了一系列 key-value,其中 key 为 docId,value 为空、或权重或特征(如 bm25 需要的词频等信息),在 Vespa 中倒排表由 PostingStore 管理。
举个例子,假设引擎中现在存储多篇文档,如下。
[
{"0": "foo bar"},
{"1": "bar zoo"},
{"2": "foo zoo"}
]
会构建如下所示的倒排索引:
我们从最下层的倒排表开始介绍。
PostingStore
PostingStore,倒排表的管理类,是 Vespa 列存的一部分,每一列也即每个需要构建倒排索引的字段都持有一份 PostingStore。
PostingStore 是对 DataStore 这一 Vespa 通用容器的封装,向 DataStore 中存储某个实例会得到一个 uint32_t 类型的 id,同样能够通过该 id 获取到存储的实例,具体实现暂按下。
数据结构
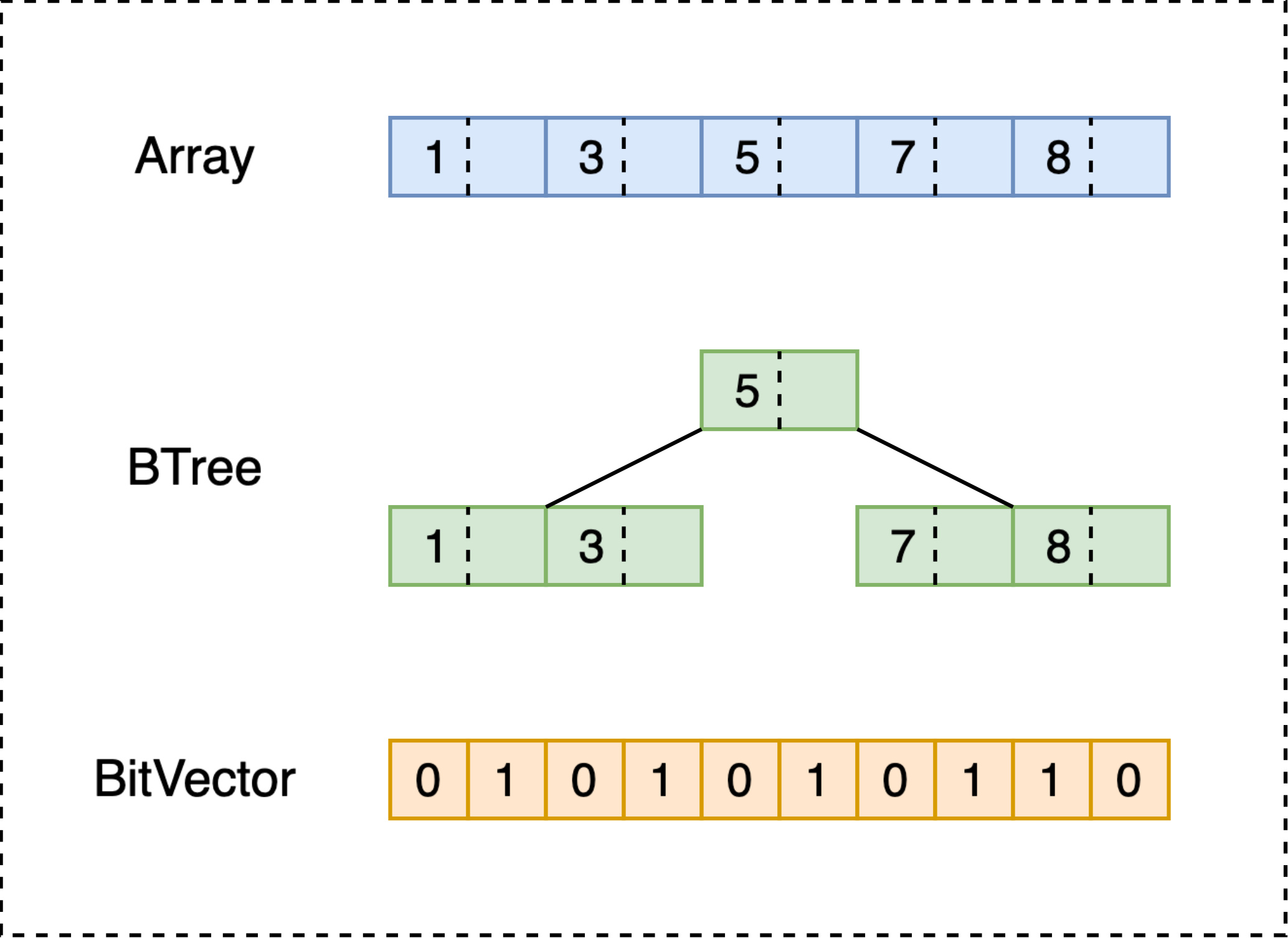
通过 DataStore 提供的接口,PostingStore 持有了这一列所有倒排表,每个倒排表根据大小和配置的不同,使用不同的数据结构存储:
最通常状态下,倒排表以如上图中 B-Tree 的形式组织:
从文档写入的角度来讲,增删的复杂度都相对较低;
从查询的角度来讲,B-Tree 是可遍历的,且对内存访问较友好;
值得注意的,插入或删除一系列文档时,若完全重新构建的开销更低,则不会选择直接插入;公式: $$ buildCost = treeSize * 2 + additionSize $$ $$ modifyCost = (log_2(treeSize + additionSize) + 1) * (additionSize + removeSize) $$
当倒排表长度小于 8 时,B-Tree 会被替代为简单的数组,可以在几乎不影响查询性能的情况下,减少写入的开销。
当长度大于 max(128, 文档数 >> 6) 时,会在 B-Tree 外构建 BitVector:
- 优点:极大地加速了匹配速度;
- 缺点:只能确定是否包含某个文档,无额外空间容纳每个文档额外的数据,如权重等这些在相关性分数计算时需要的数据;
- 由于以上的缺点,只有在 query 不参与相关性分数计算、只用做过滤时,才能使用 BitVector 进行高效率地匹配;
- 当然如果在配置中声明该字段就只参与过滤,便不会构建 B-Tree,提高写入性能。
Value
以上是基础倒排表存储结构。在以上描述中,忽略了 B-Tree 中 value 位置的数据。
- Value 位置的数据最大为 32 位;
- 在最容易理解的场景,value 代表的含义可以是这个 term 在这个文档内的重复次数,或是 weightedSet 这一类型数据中的权重,这两种场景均可以用 uint32_t 或 int32_t 表示;
- 可以为空;
- 当代表的内容数据大于 32 位时,此处只存储一个 id,通过此 id 可以去另一个数据结构中获取到原始的数据内容。这种场景通常是经过分词、normalization、stemming 后的文本,需要存储每个 term 的 position、occurence 等,后续可能参与如 bm25 分数计算,可参考 FeatureStore 代码了解更多,不具体展开。
Dictionary
这一部分代码逻辑基本体现在 EnumStoreDictionary。
Dictionary 存储了从 term 到倒排表 id 的映射。其支持 BTree 或 hash 两种索引结构,也可以同时存在,具体选择哪种,需在配置中显示定义。
默认情况下使用 BTree 结构,BTree 在支持前缀匹配、范围查询的情况下,提供了较合理的查询性能。
当 dictionary 所指的字段唯一性较高时,推荐使用 hash 索引,比如该字段是文档的主键时。
数据存储
上一节是特化的用于倒排索引的数据结构,这一节介绍其它在 Vespa 中用到的。
DataStore
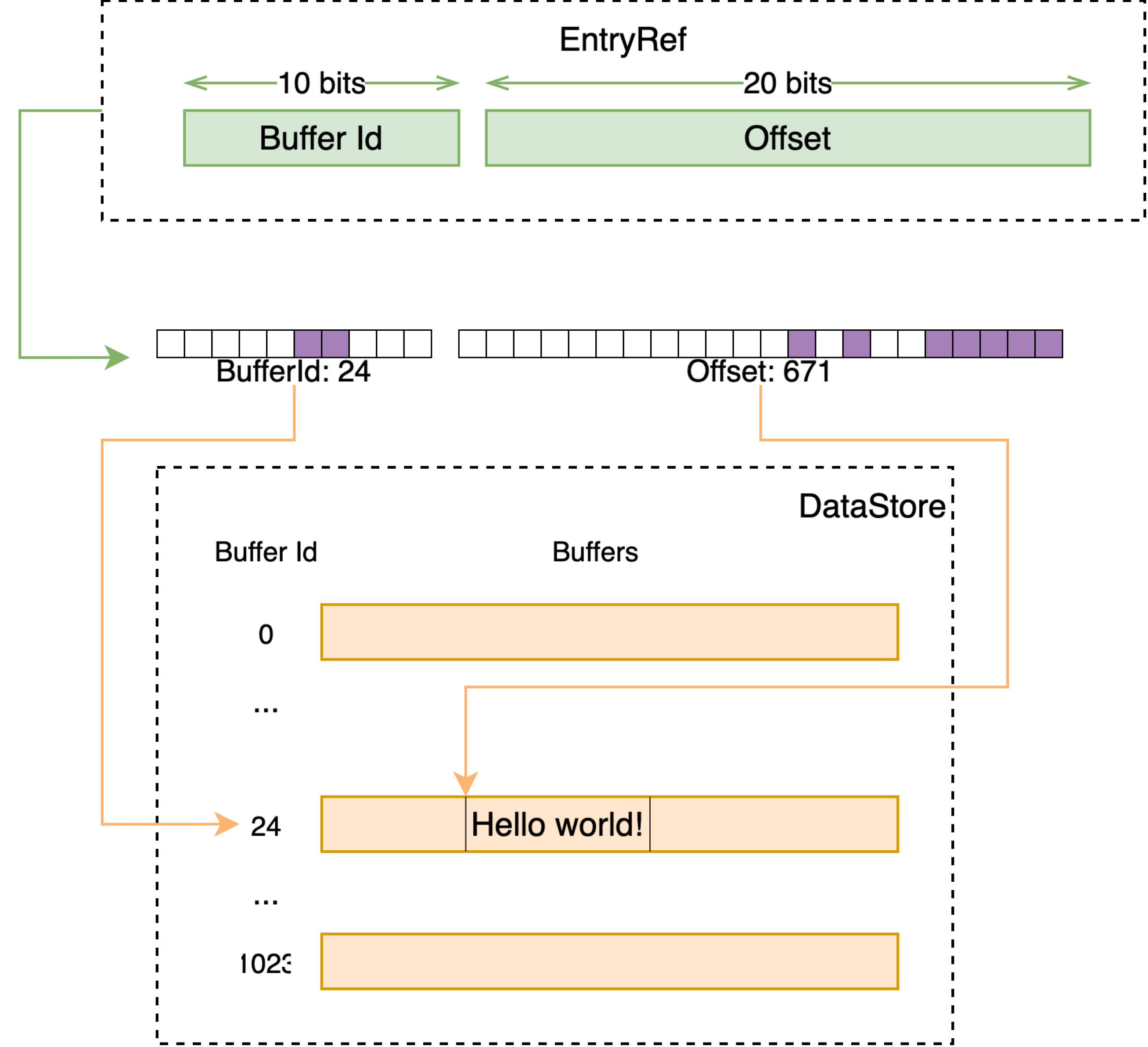
DataStore 是 Vespa 中的通用容器,向其中存储一段数据会得到一个唯一 id,之后可以通过这个 id 获取到之前存储的数据。
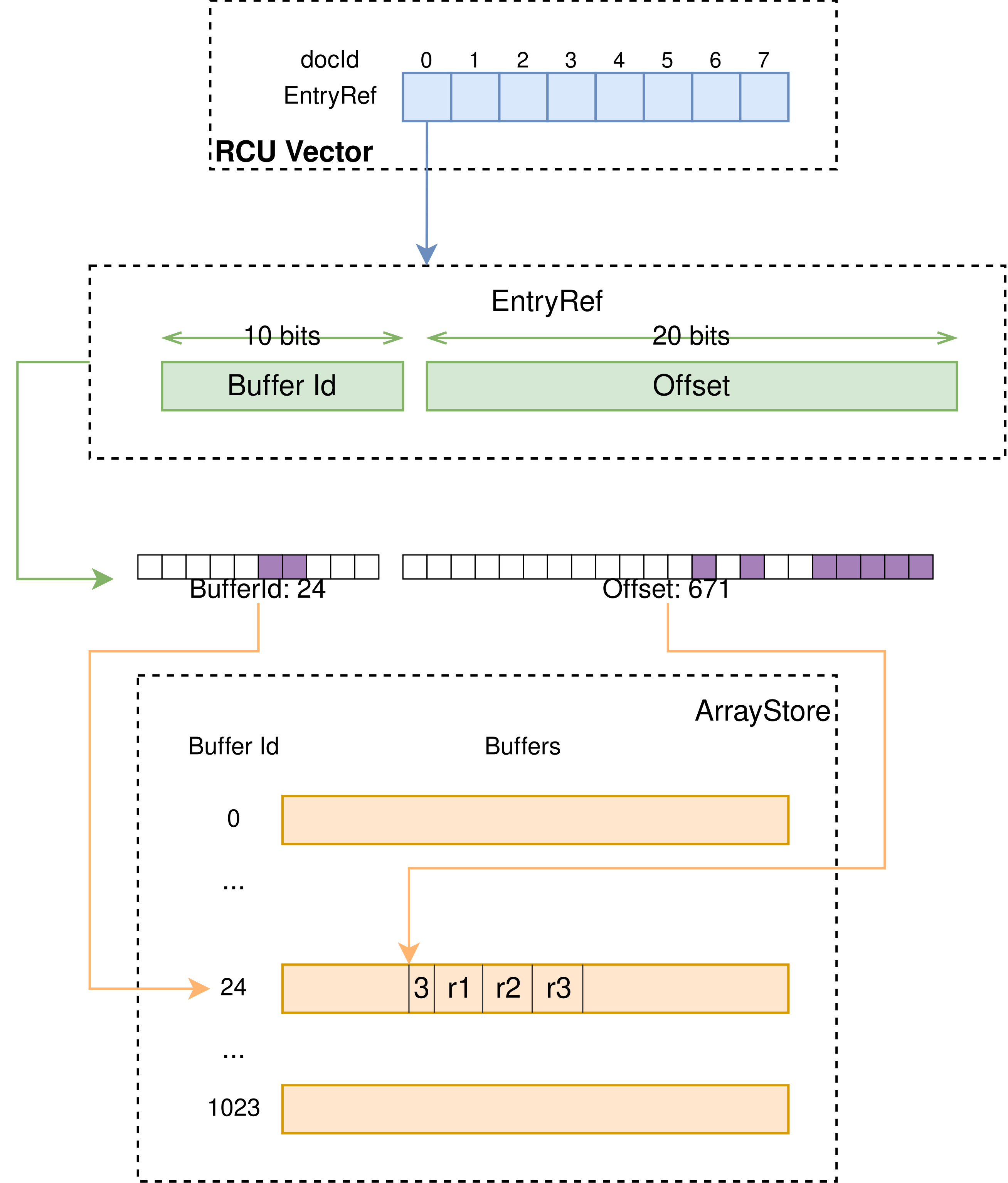
其接受的 id 类型为 EntryRef,本质上是个 32 位的 id,在这个类型的定义中,默认情况下将前 10 位视为 buffer id,后 22 位为一个 buffer 内的 offset。DataStore 于是持有 2^10 即 1024 个 buffer,每个 buffer 可持有不同类型的数据。
当插入数据时
- 检查 free list 中是否有之前已释放的槽位;
- 检查当前插入的数据类型所指向的 active buffer 是否有空闲空间,否则切换到新的空闲的 buffer;
- 找到空闲的 buffer 后,定位至空闲的 offset,插入数据至此处;
- 此时 buffer id + offset 即构成了返回的 entry id。
当通过 entry id 获取数据时,即是线性地,将 entry id 分为 buffer id 和 offset 即可定位至相应的数据。
ArrayStore
ArrayStore 是基于 DataStore 上封装的支持单一类型、不同数组长度的数据结构。
EnumStore
EnumStore 在使用了 DataStore 的基础上,可以使用 EnumStoreDictionary 赋予了在这一系列数据(string, int 等 primary type)上进行快速查找的能力。
数据被直接地存储在 DataStore 中,而 EnumStoreDictionary 以这些存储的值为 key,value 中存储了其在 DataStore 中的 id 和对应的倒排表 id。
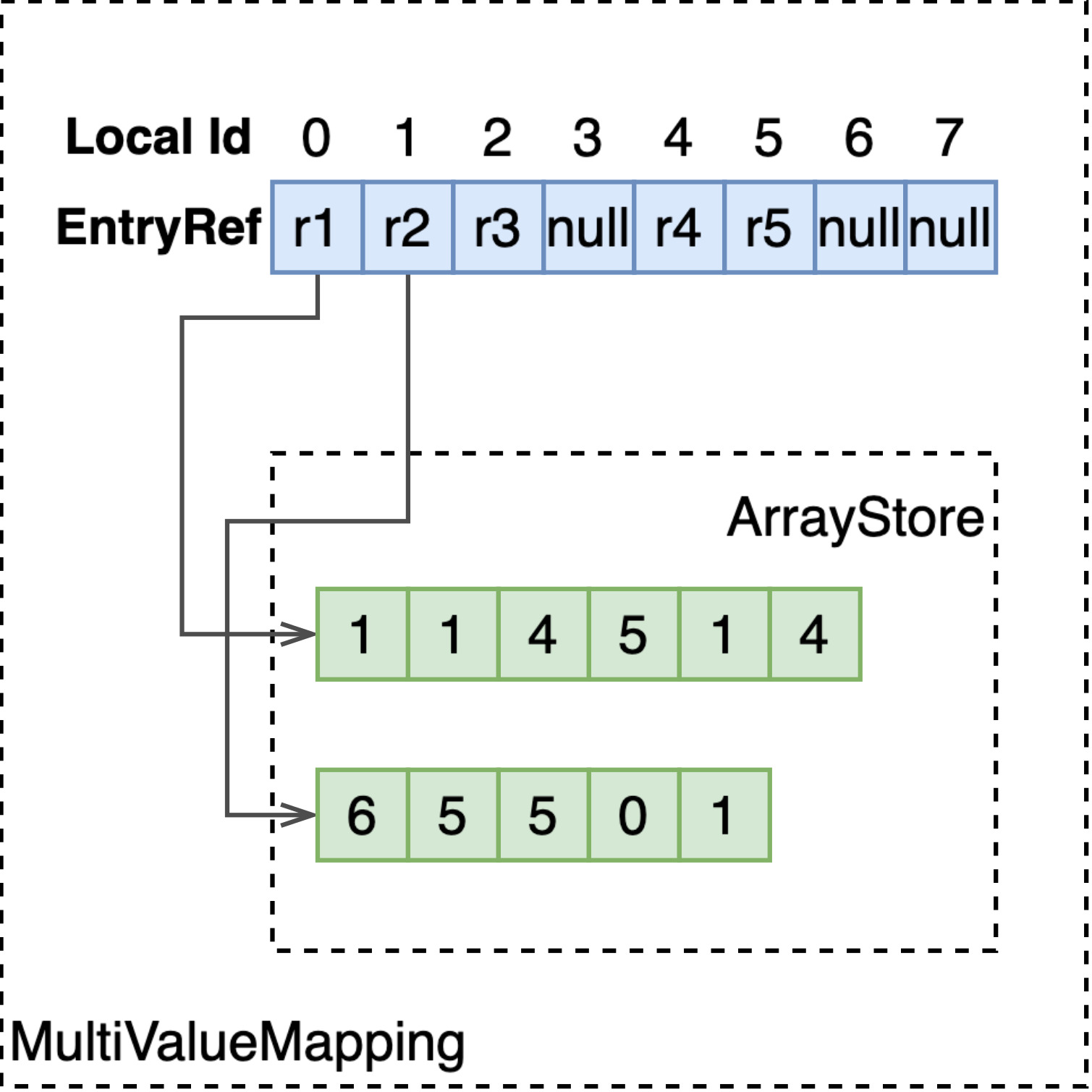
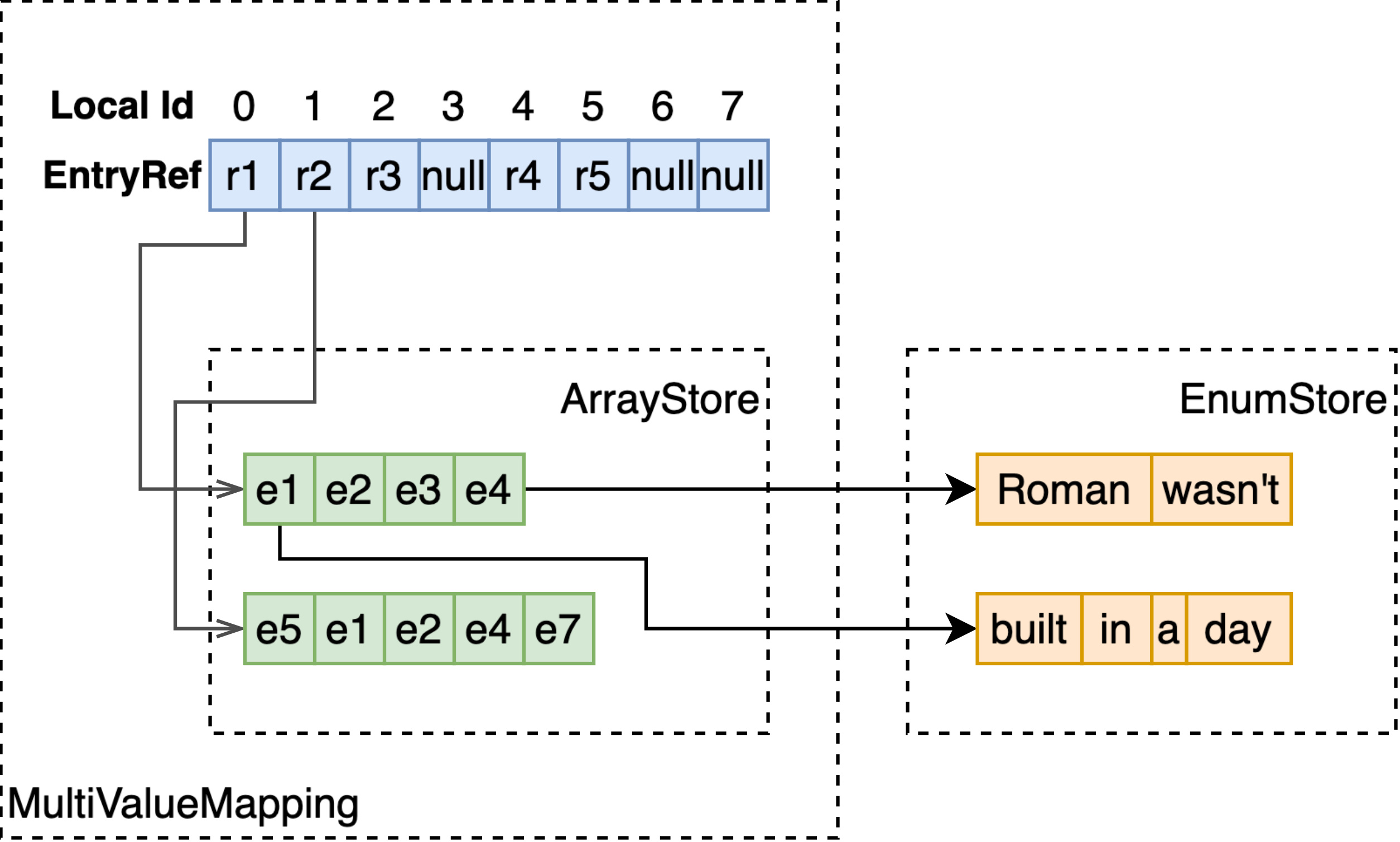
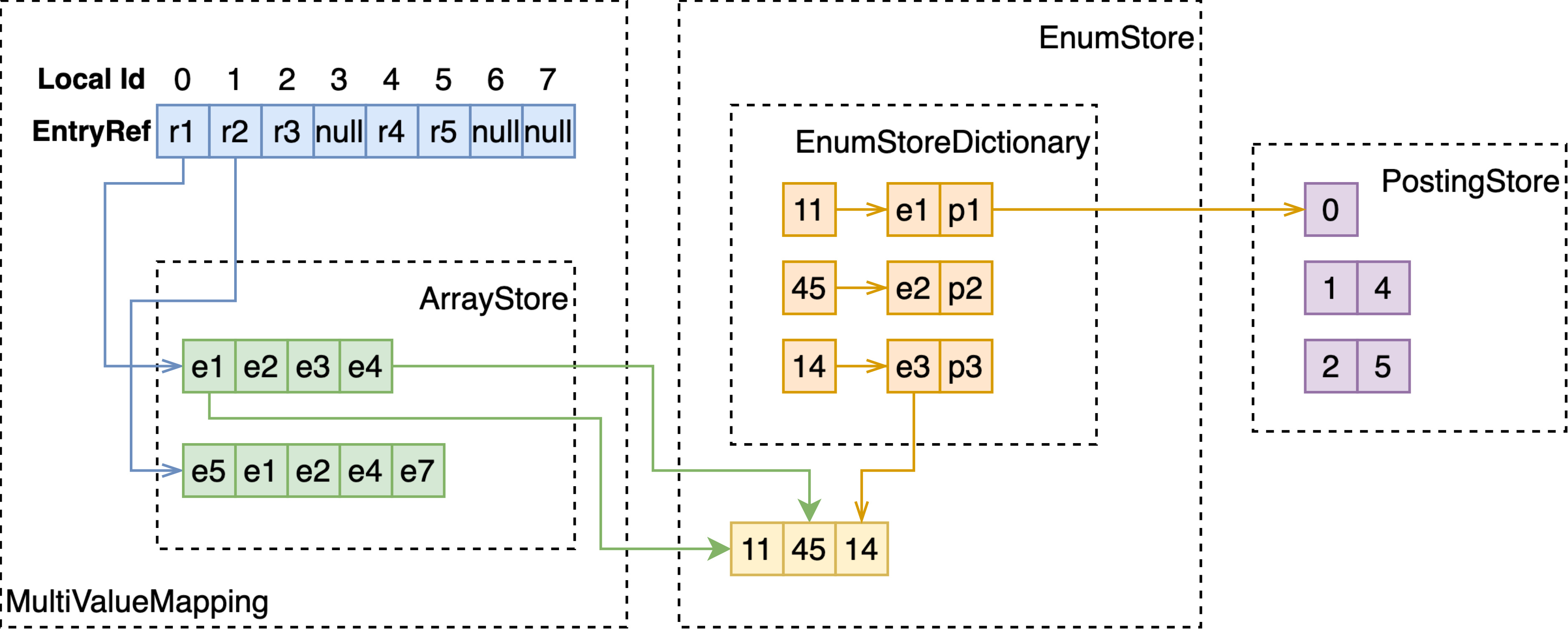
MultiValueMapping
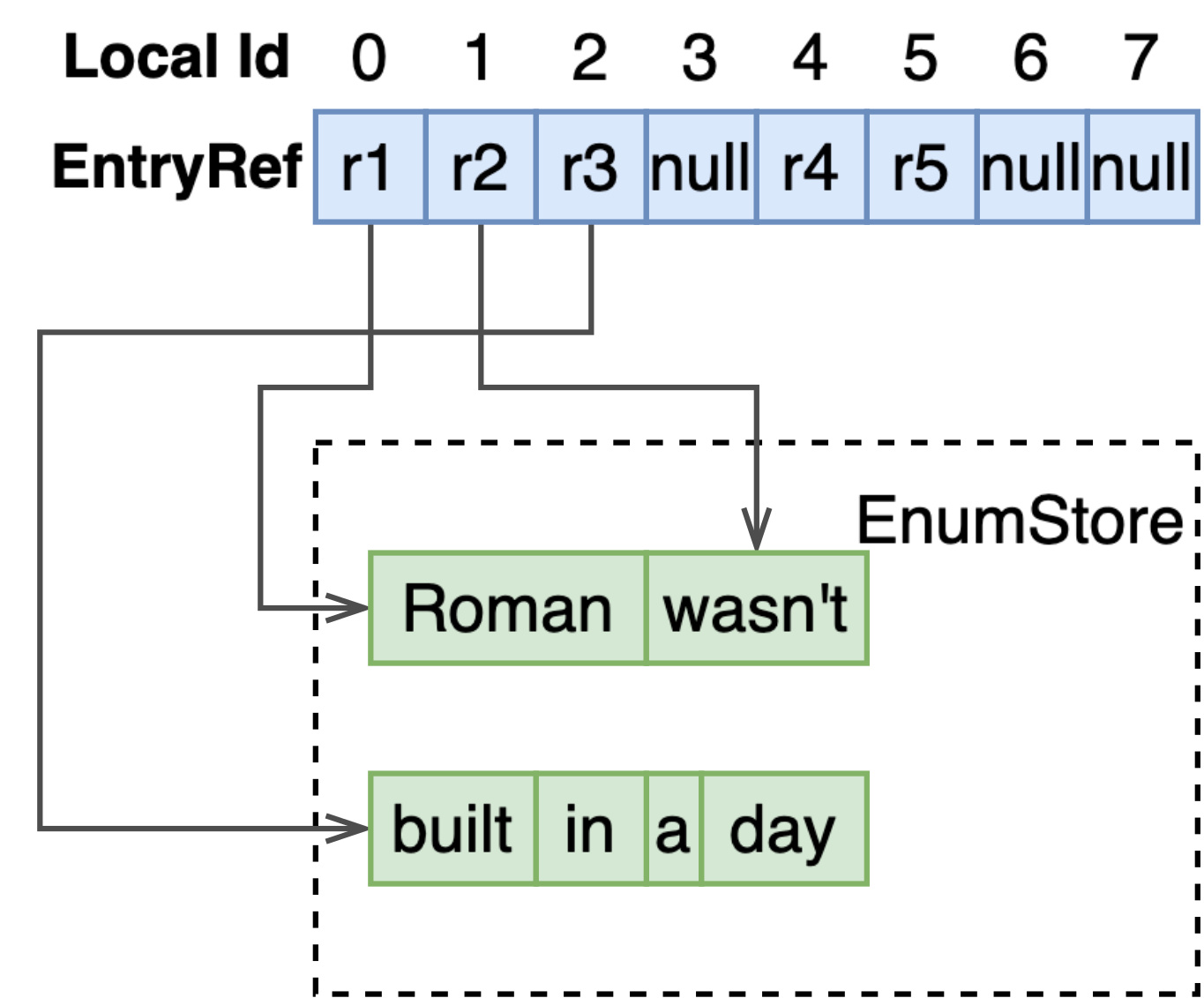
EnumStore 只能支持单值字段的存储与检索,为了支持多值字段,如 array<int>、array<string>、weightedset<string>,MultiValueMapping 基于 RCUVector 和 ArrayStore 构建了 local docId 到多值字段值的映射。
如上图所示,RCU Vector 以 docId 为序号,存储指向 ArrayStore 的 EntryRef。通过 EntryRef,能够获取到 ArrayStore 中存储的定长或变长的数组。
注意 ArrayStore 存储的数组,每个元素的长度是固定的,因此如果要存储多值 string 类型,要将字符串存储至额外的 EnumStore,这里只存储指向 EnumStore 的 EntryRef。
Attribute
在了解以上的数据结构实现后,我们介绍 Vespa 中最常用的索引结构之一,attribute。
最基本的情况下,attribute 选项要做到的是把这一列数据全量地放在内存中,便于:
- 在 fetch 阶段更快地获取每个 doc 这一 field 的值;
- 只有开启了 attribute 选项的字段才能使用 grouping,ranking,sorting 等功能;
- 在此基础可以选择构建倒排,用于结构化数据的匹配。
我们由简到繁介绍不同情况下 attribute 的实现,主要的变量是两个:
- 值是否是固定长度,如 int/float/double 为固定长度,string 为变长;
- 单值或多值,如 int、string 为单值,array<int>、weightedSet<string> 为多值;
- 是否需要构建倒排,加速查询。
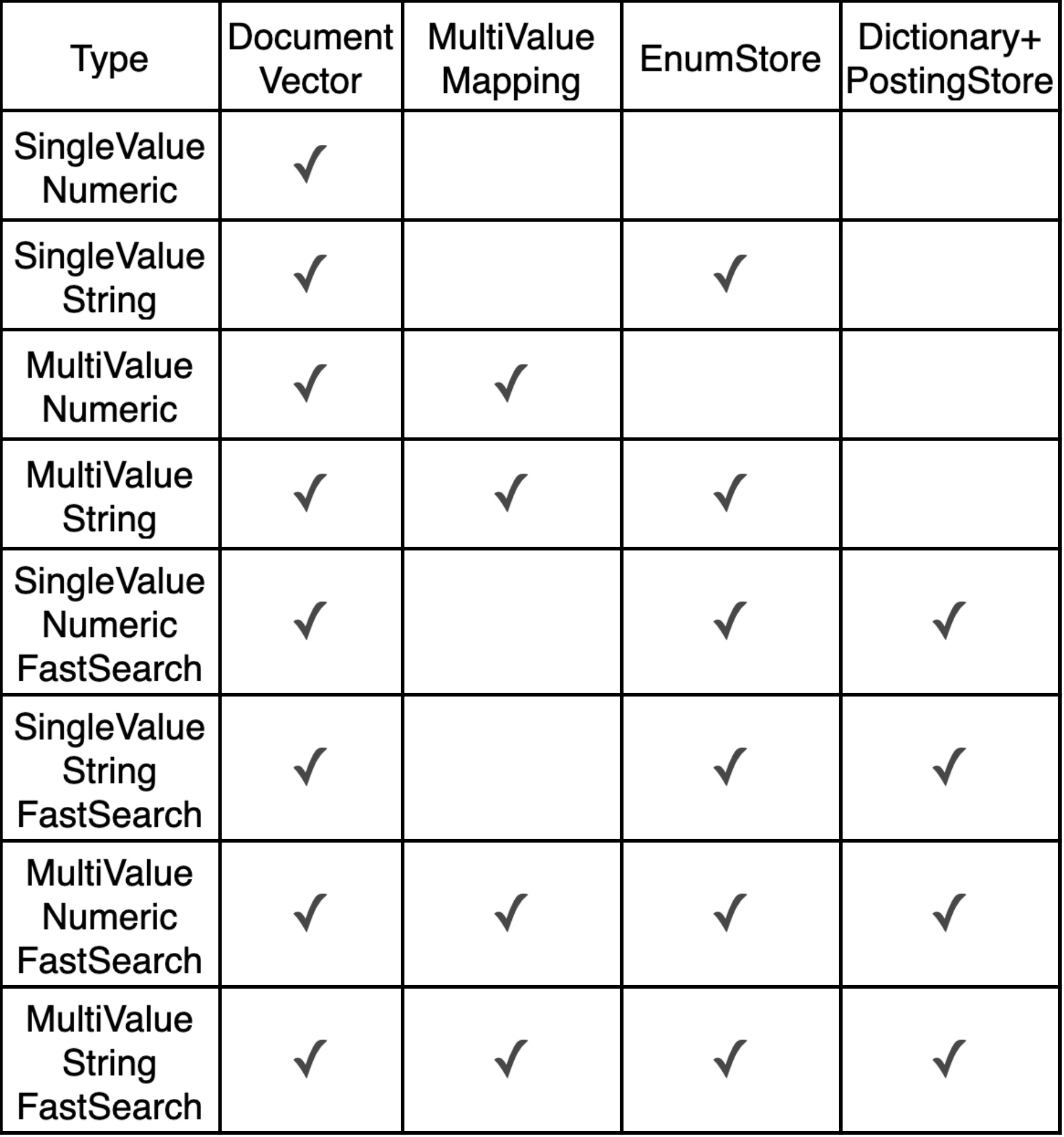
以上这张表中列出了不同类型会使用到的数据结构,具体实现请往下看。
SingleValue-Numeric
首先说明,在向 Vespa 写入文档时,需要指定文档 id,这个 id 通常被称作 global id。实际上的内存存储中,global id 会转换为 local id。global id 可以是满足 pattern 的任意字符串,而 local id 则是从 0 开始递增的,这样,以 local id 为数组序号,可以在一个数组中密集地放下一个字段所有文档的值。随着较小 local id 文档的删除,local id 空间的空槽比例会增加,vespa 会在后台自动地压缩 id 空间。稍后我们会详细讲述这个数据是如何存储的。
单值、数字(也就是定长)、不构建倒排,只需要简单的 RCU Vector 即可。

SingleValue-String
基于 SingleValue-Numeric,变长的字符串需要存储在额外的 EnumStore 中。
MultiValue-Numeric
与 SingleValue-Numeric 不同,这里使用了 MultiValueMapping 直接地存储数组。
MultiValue-String
SingleValue-Numeric-FastSearch
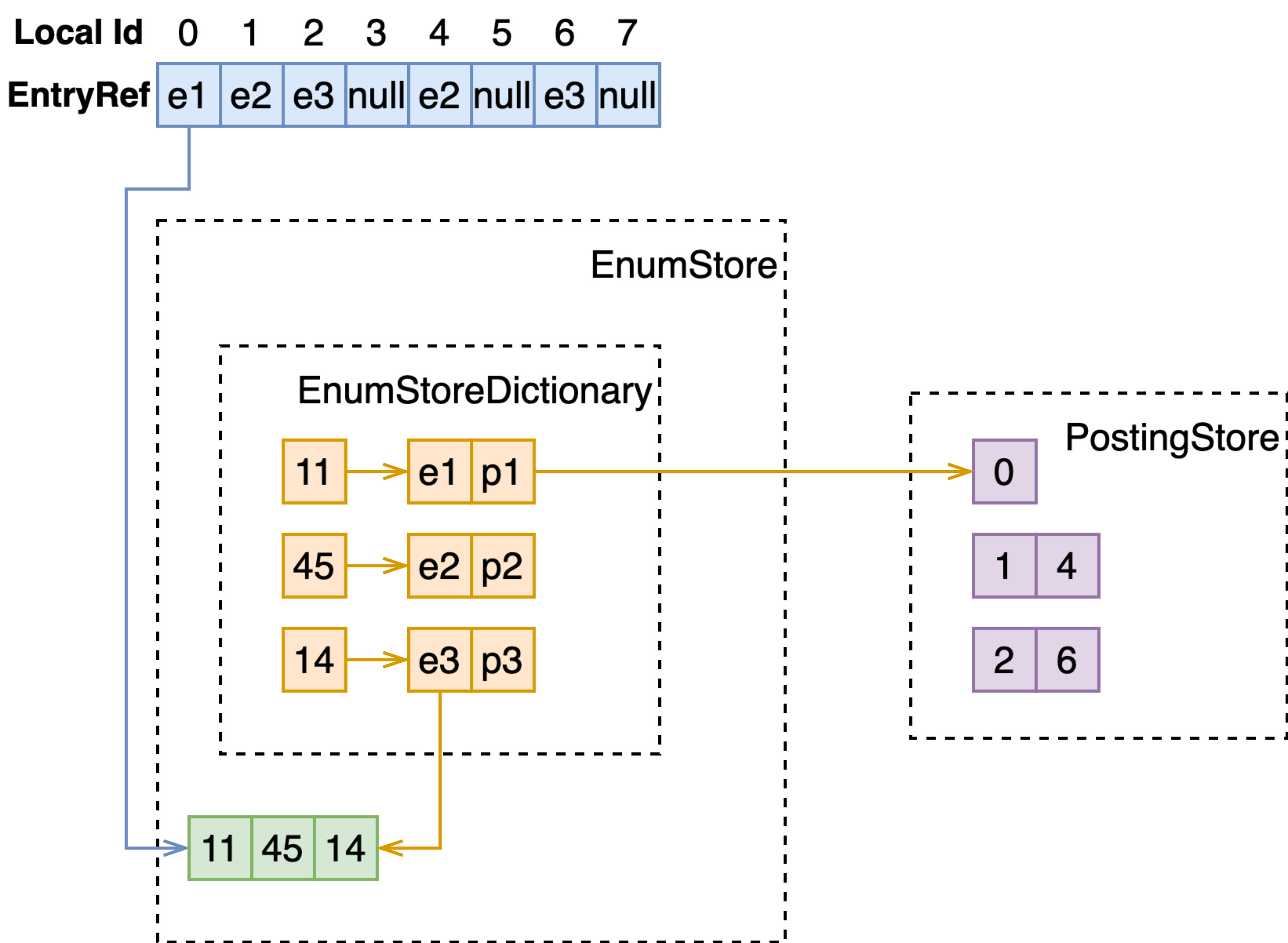
FastSearch 即是要倒排,这里的话,即便值类型是定长的,依然将其存储在 EnumStore 中,而不是直接存储在 document vector 中,取而代之的是指向 EnumStore 的 EntryRef。
在文档写入时,需要分别构建 DataStore,PostingStore 和基于这两者之上的 EnumStoreDictionary。
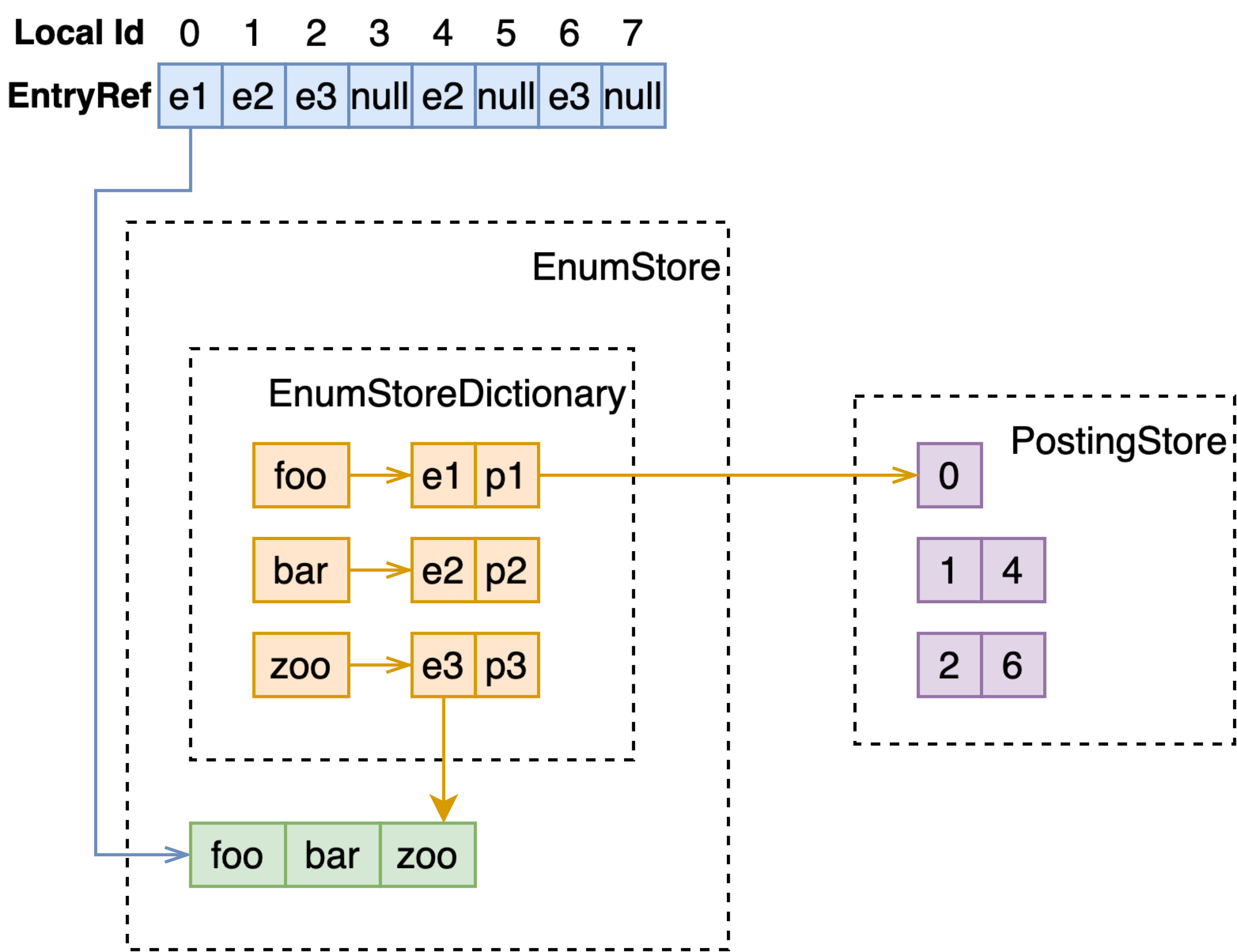
SingleValue-String-FastSearch
单值、变长、fast-search 的实现与定长时的实现是一致的。
MultiValue-Numeric-FastSearch
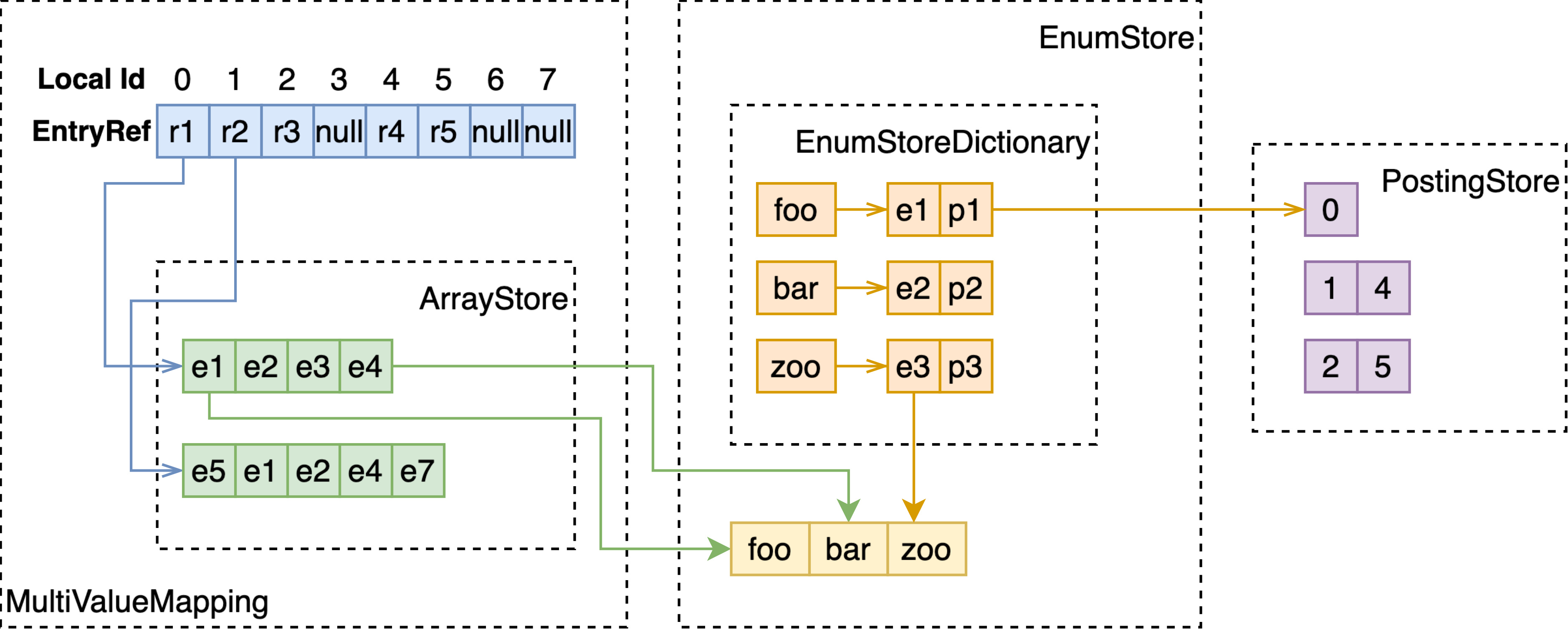
MultiValue-String-FastSearch
Index
Index 是 Vespa 中另一主要的索引方式。与 attribute 不同,使用 index 索引方式的字段,会经历 tokenizing、normalizing、stemming,即会把一整段文字进行分词归一化等操作,这样的索引方式显然是为像网页文本搜索服务的。
index 只会构建倒排索引,不会额外存储全量的数据。且倒排索引不会全部放在内存中,会有相当一部分存在于磁盘上。当文档写入时,会先更新内存中的 memory index,memory index 会定期写入磁盘(flush),然后和已有的磁盘上的 disk index 合并(fusion)。当检索该字段时,需要同时查询 memory index 和 disk index 后合并结果。
我们先从内存中的那部分开始。
Memory Index
Memory index 的数据结构非常类似于 attribute 中的 MultiValue-String-FastSearch,不同的是:
- 不需要另外存储全量数据,于是没有 DocumentVector 和 MultiValueMapping;
- 经过 tokenizing 的文本,会带有如词频、位置等信息,用于之后的 bm25、nativeRank 计算,故会有额外的 FeatureStore 数据结构存储这些特征信息,在 PostingStore 中成对存储了 docId 和指向 FeatureStore 的 EntryRef。
- Attribute 可以配置 dictionary 使用 hash 或者 BTree,memory index 则只有 BTree 这个选项(很容易理解的:index 索引的文本通常并不具有高唯一性)。
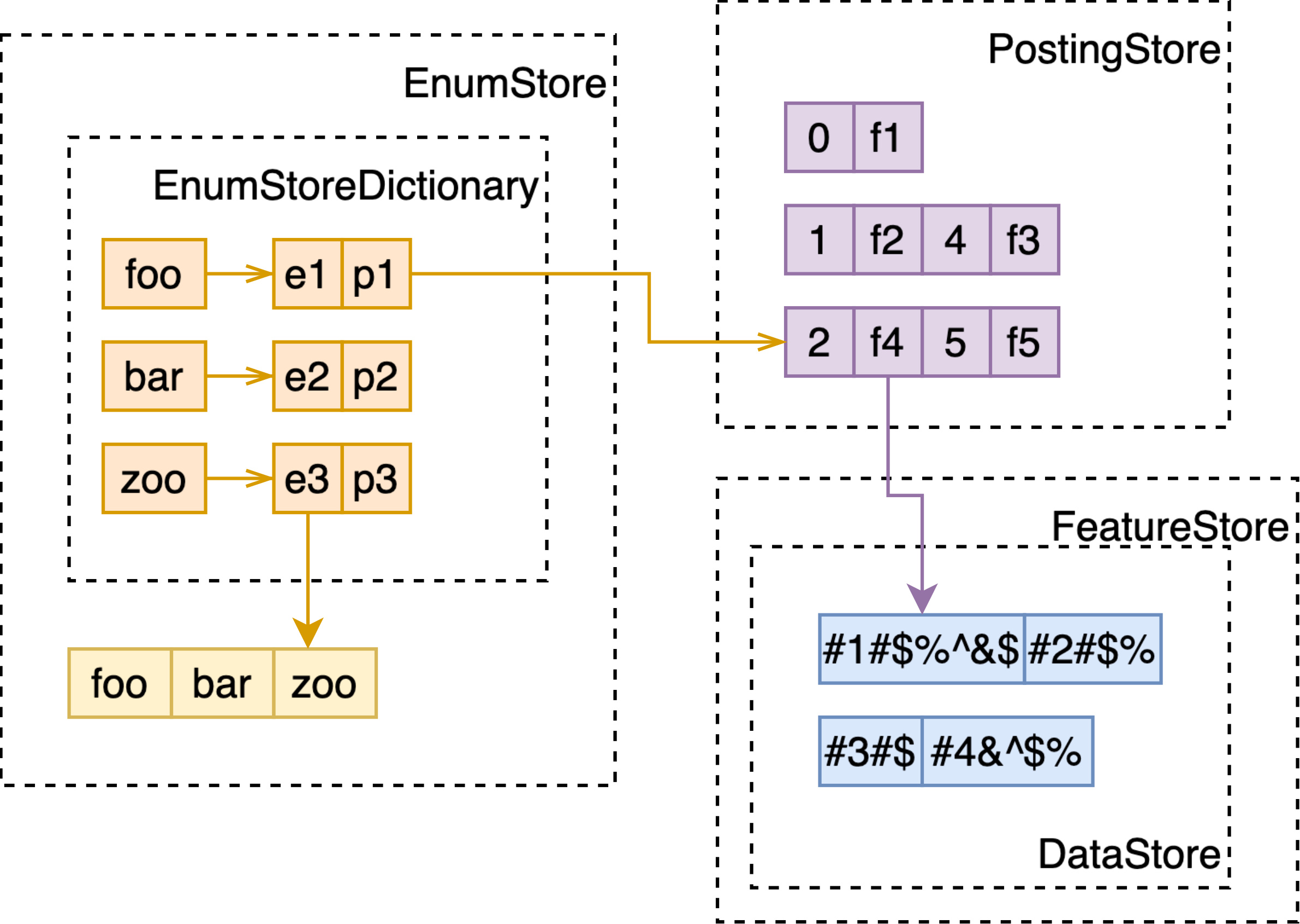
Disk Index
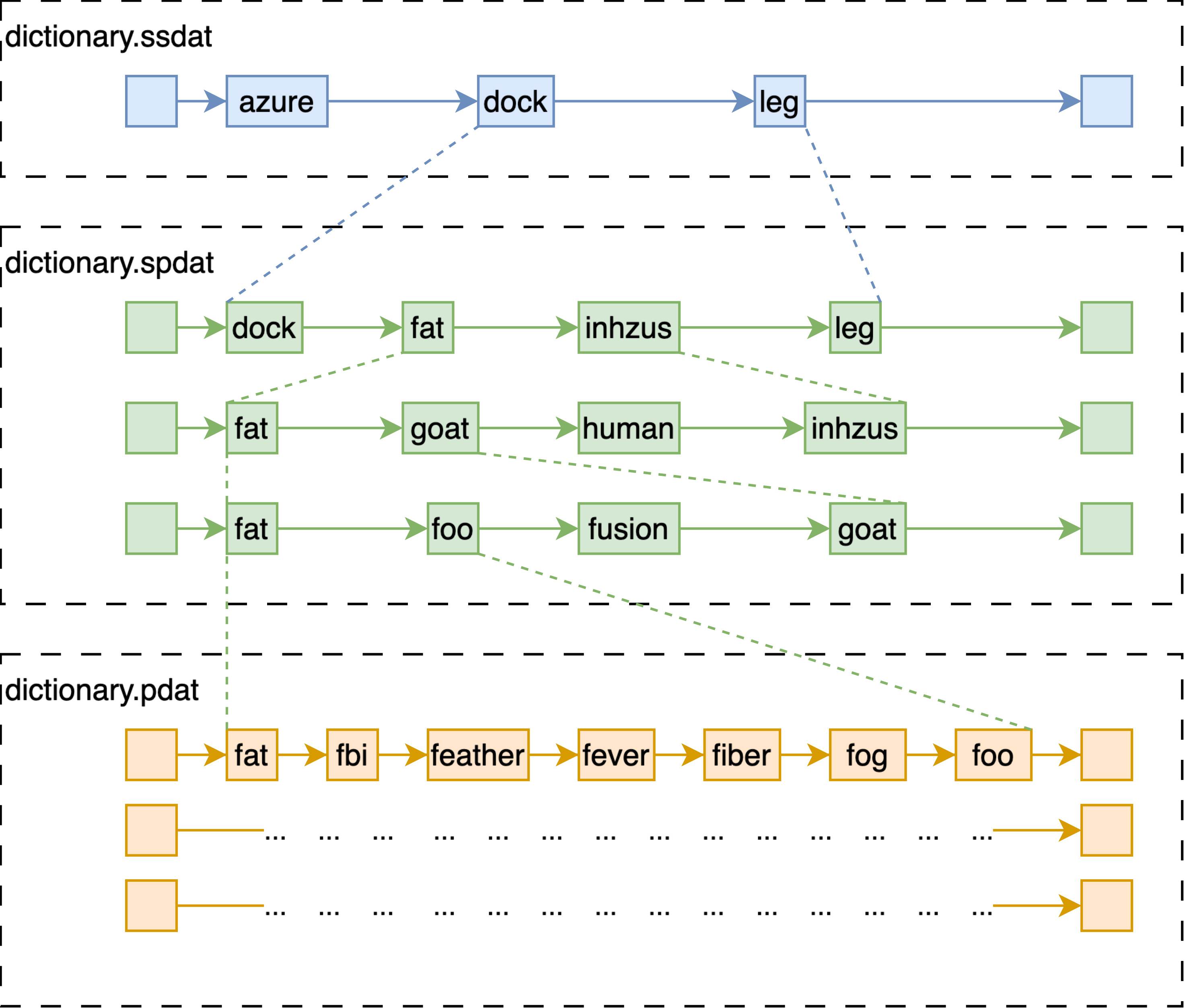
- Disk index 等价于 memory index 的 EnumStore 在磁盘中的结构等价于七层跳表;
- 跳表的最上层,文件名以 ssdat 结尾,会被全量加载至内存中;
- 中间三层和下边三层,分别存储在两个文件中,以 spdat 和 pdat 结尾;
- Disk index 的倒排表被压缩后存在以 dat.compressed 结尾的文件中;
- 另外还保存了精简版本的 bitvector 形式的倒排表,在不需要提取具体特征时使用,两个文件分别以 bdat 和 idx 结尾。
注意到事实上,尽管这些文件都在磁盘上,在内存足够的情况下,在我们内部的版本中,往往会 mmap 分配一块匿名内存,然后将这些文件全部映射至内存中。官方的版本提供了 populate 这一选项,也就是在 mmap 文件至内存时,尽量减少 page fault 的发生。