Vespa 索引检索实现
Table of Contents
上一文,Vespa 索引结构实现,讲述了 Vespa 构建各种索引、倒排索引使用的数据结构,本文将介绍检索是如何基于这些数据结构进行的。
宏观视图
我们首先从宏观,自顶向下地介绍一次检索需要经过那些步骤。
众所周知,客户端发起的一次请求,在 QRS 上会分为两阶段进行,大部分任务在第一阶段完成:匹配、记分、排序等等,最终会返回给 QRS 这一轻量级的服务以 doc ids 及其它信息,QRS 上会对多个分片上的 doc ids 排序归并,到第二阶段时,向 content 节点请求这些 doc ids 的正排信息,以减少不必要的 IO。
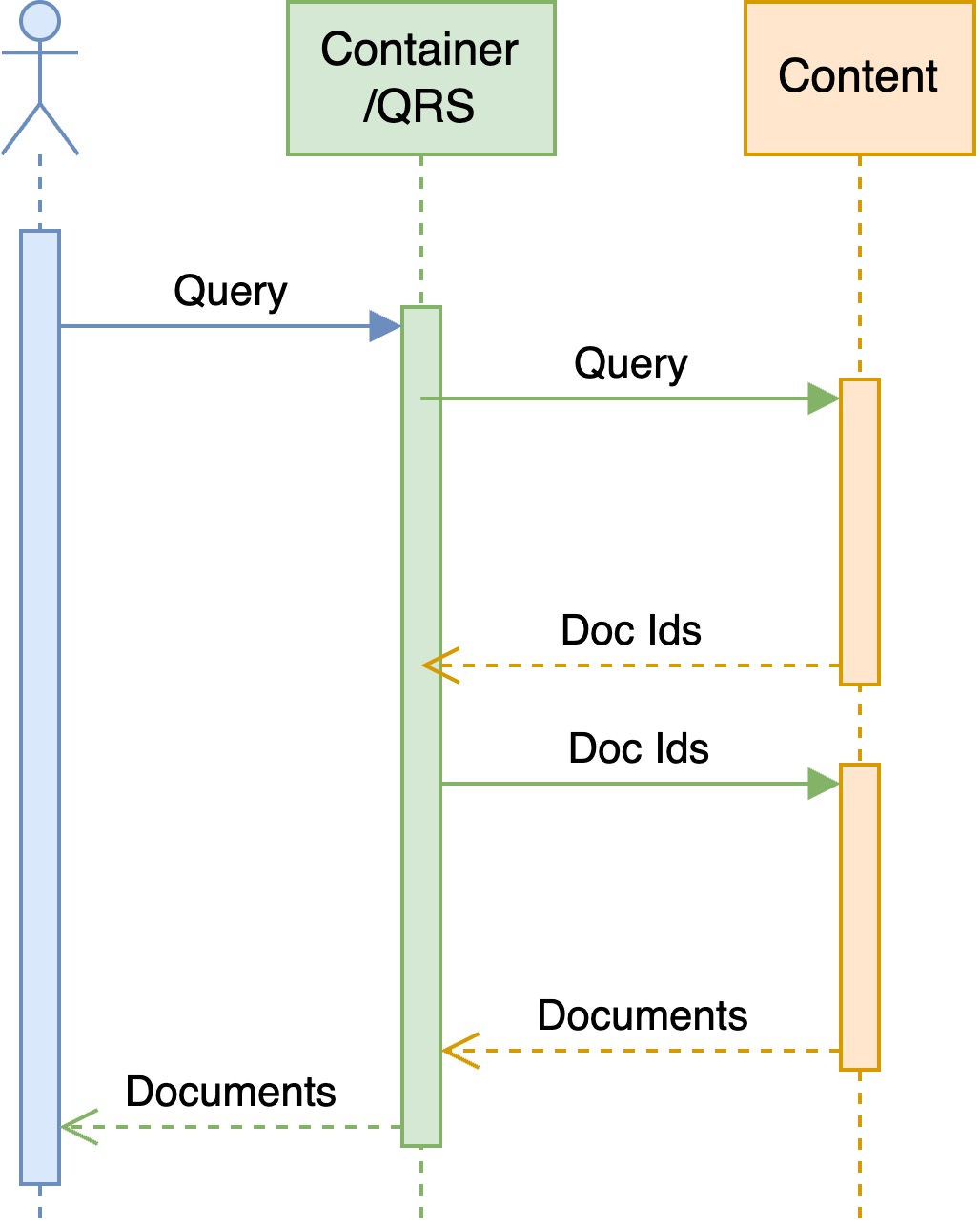
我们重点关注第一阶段中的匹配过程。
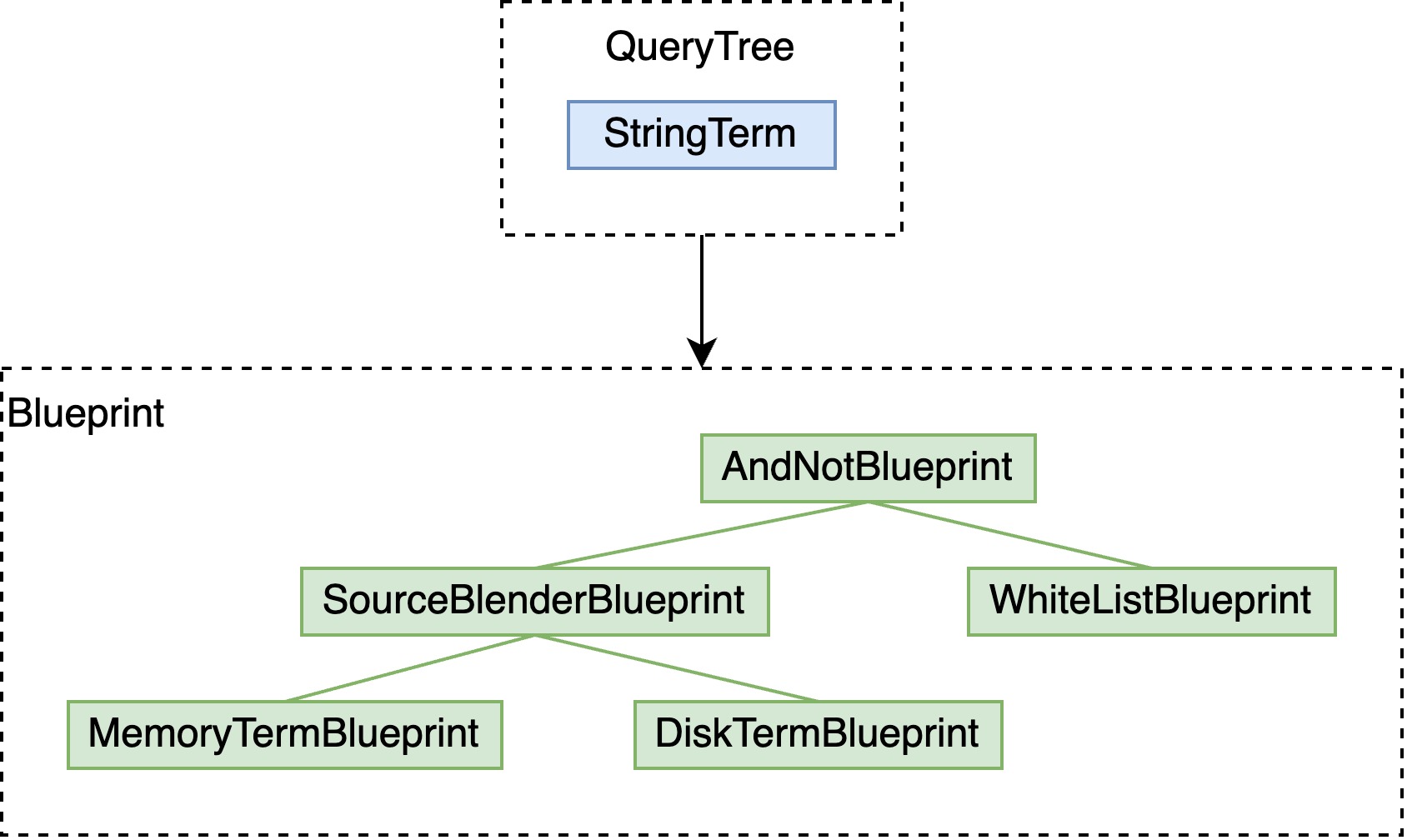
- 经过前边的不论是 container 或 QRS 的构造,将用户的输入,转化为一棵便于 Vespa 处理的语法树,这里通常会展开优化;
- 将 QueryTree 构造为 Blueprint,借用数据库中的概念即逻辑执行计划。实际实现中,如果检索的字段有倒排索引的话,此时已经通过 dictionary 定位到相应的倒排表,于是可以确定这些 Blueprint 是否查询到了相应的 term 及预估文档数量,在此基础上,可以进行剪枝、pre/post filter 等优化;
- Blueprint 可以创建出同样树状的 SearchIterator,即物理执行计划。
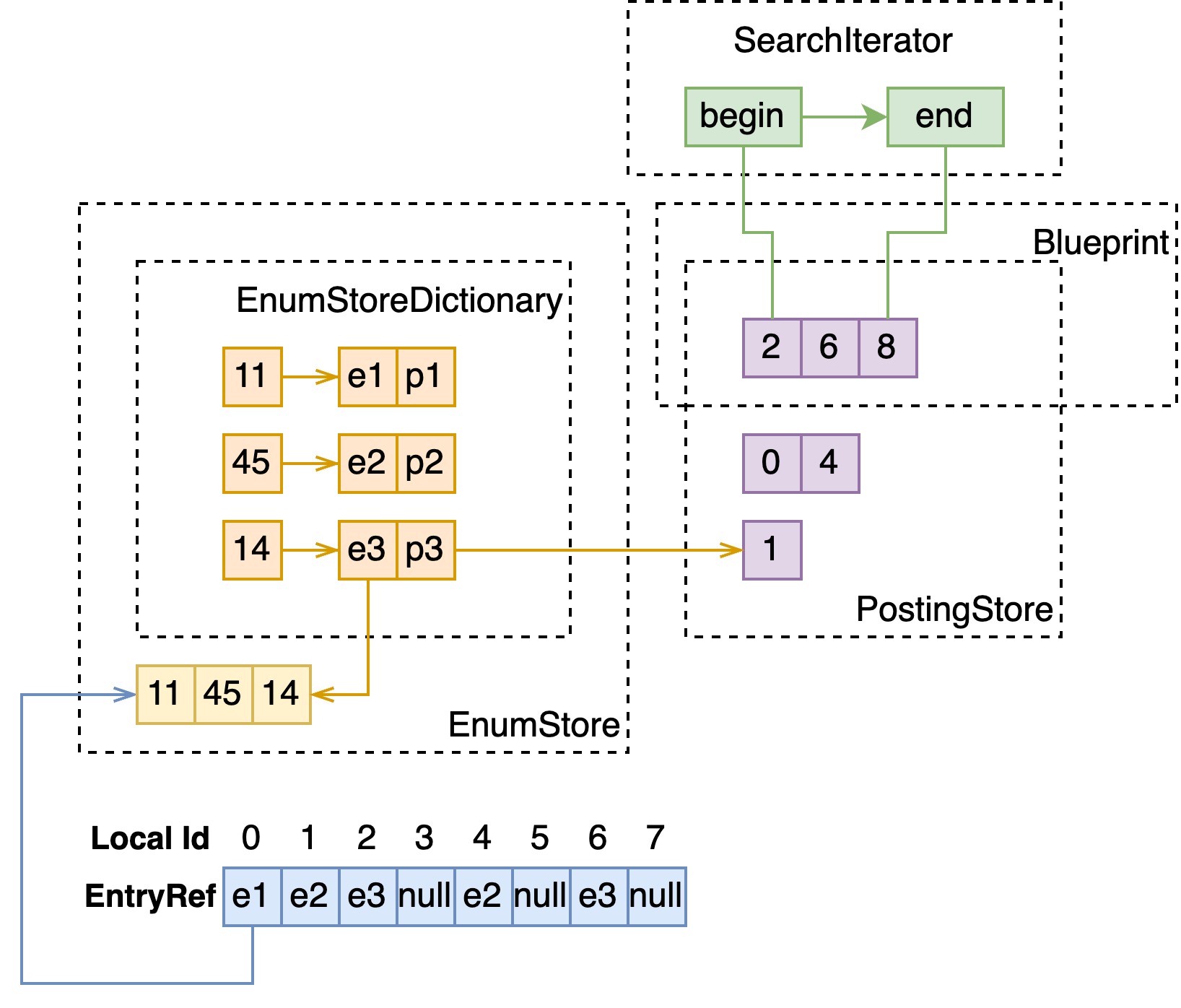
下图中是一个简化的从 YQL 到 QueryTree、Blueprint、SearchIterator 的实例。
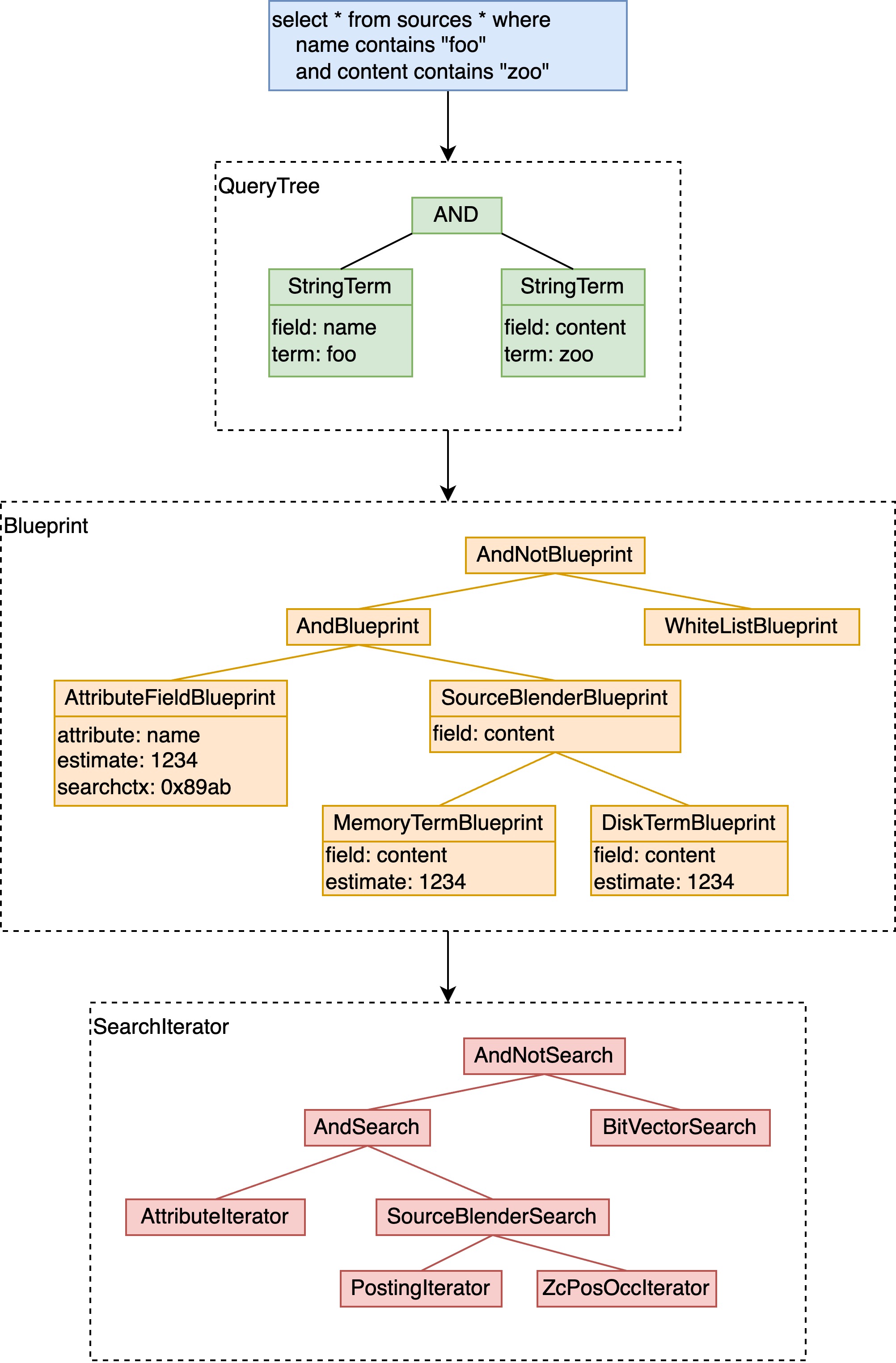
更详细地来说,Blueprint 树会构建若干个 SearchIterator 树用于每个 match thread 使用,匹配时会将本机的 local doc id 空间,按 thread 数量分为若干段,每根 SearchIterator 树在在这段 local doc id 空间上从低位至高位匹配,同时 unpack 出相关性分数计算需要的数据,ranking 部分会据此同时计算出每个文档的分数。
uint32_t MatchThread::inner_match_loop(Context &context, MatchTools &tools, DocidRange &docid_range) {
SearchIterator *iterator = &tools.search();
search->initRange(docid_range.begin, docid_range.end);
while (docId < docid_range.end) {
if (do_rank) {
search->unpack(docId);
context.rankHit(docId);
} else {
context.addHit(docId);
}
docId = search->seekFirst(docId + 1);
}
return docId;
}
这里我们注意到 SearchIterator 的三个方法
initRange:初始化或重置一些内部类及子 iterator 的状态;seekFirst:线性地找到下一个匹配条件的 docId;unpack:将从倒排表中读到的相关性分数需要的数据存储在临时变量中,用于另一根分数计算的 Blueprint 使用。
关于其中的 seekFirst,我们简单展开介绍。实现部分,大体可以分为如下几种:
- 无倒排的叶子节点:线性地逐个取出文档判断是否匹配;
- 有倒排的叶子节点:在倒排表中读出下一个 docId;
- 中间节点:递归地推动子节点向前匹配,对于 And、Or、AndNot 均有不同的实现。
然后是很重要的 strict 这一概念,事实上,没有必要让所有的 SearchIterator 都线性地在 docId 空间或者倒排表上前进。可以选择让其中一部分 SearchIterator 线性地前进(即 strict),另一部分只探测这些 docId 是否匹配。以简化后的 SearchIteratorBitVector 代码为例:
// strict
void BitVectorIteratorStrictT::doSeek(uint32_t docId) {
docId = getNextBit(docId);
this->setDocId(docId);
}
// non-strict
void BitVectorIteratorT::doSeek(uint32_t docId) {
if (isSet(docId)) {
this->setDocId(docId);
}
}
在构建 SearchIterator 树之前,会计算 strict 或 non-strict 的预期开销,选择开销更低的实现构造,实现见 searchlib/src/vespa/searchlib/queryeval/flow.h。
Term 检索
接下来我们再自底向上介绍,从最简单的 term 检索开始:
select * from sources * where name contains "foo"
这一 YQL 查询语句要检索 name 这一字段包含 foo 的文档,根据 name 字段的索引方式,分类讨论:
Attribute
无倒排
对于没有倒排的单值或多值字段,当 SearchIterator seek 至某 docId 时,从 EnumStore 取出其值进行暴力的匹配。
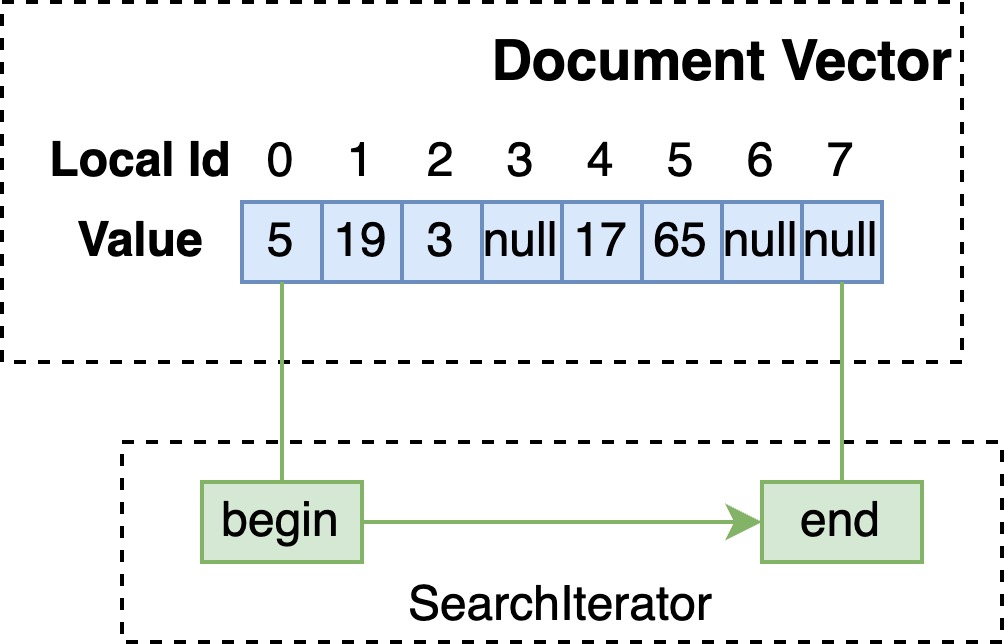
// single value
int32_t find(DocId docId, int32_t elemId) const {
T v = _enum_store.get_value(_enum_indices[docId].load_acquire());
return this->match(v) ? 0 : -1;
}
// multi value
int32_t find(DocId doc, int32_t elemId) const {
auto indices(_mv_mapping_read_view.get(doc));
for (uint32_t i(elemId); i < indices.size(); i++) {
T v = _enum_store.get_value(multivalue::get_value_ref(indices[i]).load_acquire());
if (this->match(v)) {
return i;
}
}
return -1;
}
FastSearch
当有倒排时,在构建 Blueprint 时,即会通过 dictionary 检索至倒排表,SearchIterator 在倒排表上线性地推进。
void AttributePostingListIteratorT::doSeek(uint32_t docId) {
// _iterator 为基于倒排表的 iterator
_iterator.linearSeek(docId);
if (_iterator.valid()) {
setDocId(_iterator.getKey());
} else {
setAtEnd();
}
}
Index
来到 index 索引,情况变得复杂了起来:
- Index 包括 memory index 和 disk index,需要结合这两者的结果;
- Disk index 是不可更改的,当要删除的文档在 disk index 上时,如果不借助额外的数据结构,检索时会搜到该文档。Vespa 提供的方案是,在原始构建的 Blueprint 上层,AndNot 一个 WhiteListBlueprint,WhiteListBlueprint 会读取 document store 中的 doc id bitvector,筛选已经被删除的文档。
于是,一个简单的 term query,构建的 Blueprint 会变成:
下边具体展开每项阐述。
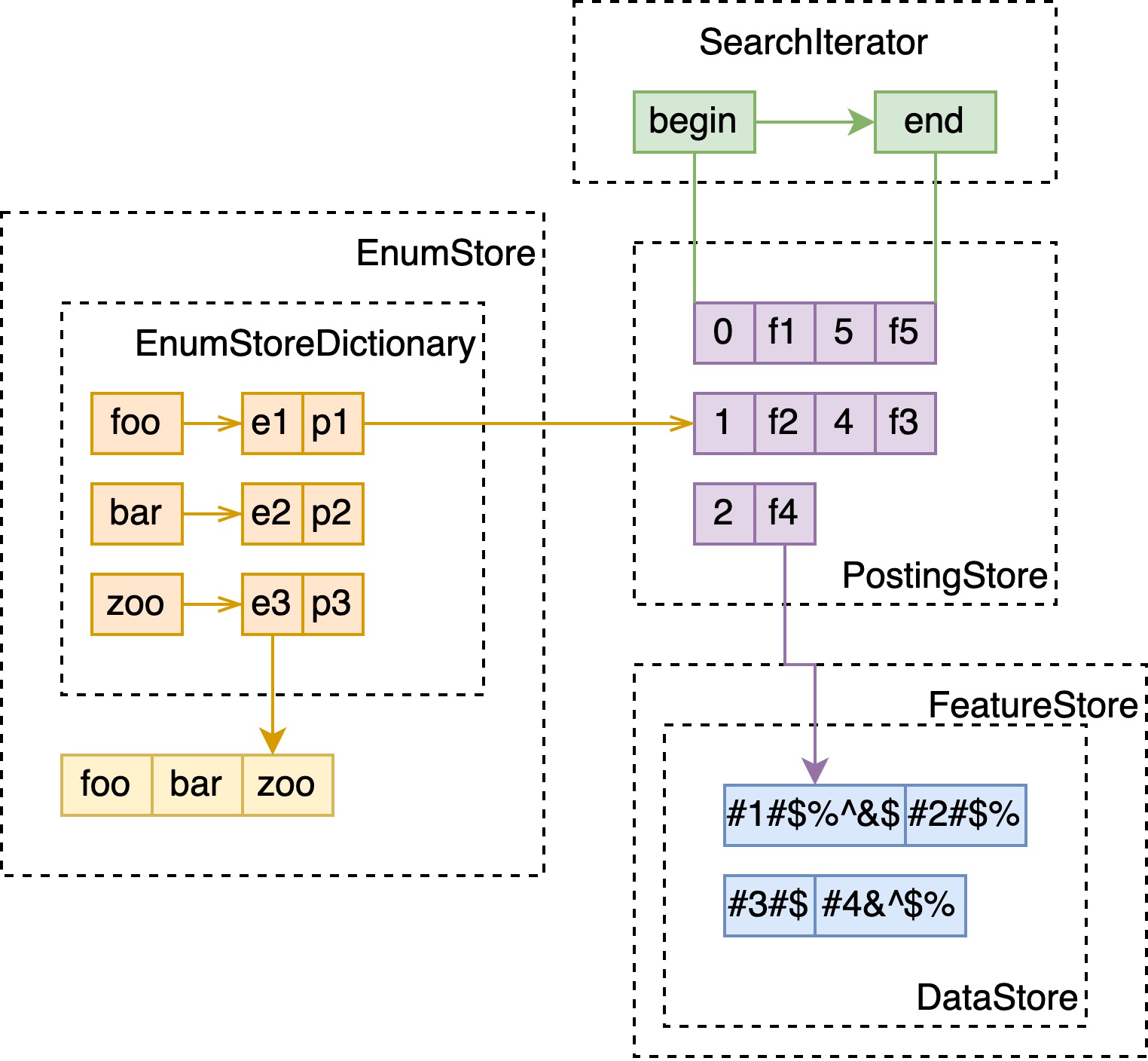
Memory Index
这里与 attribute x fast-search 几乎一致,如下图。
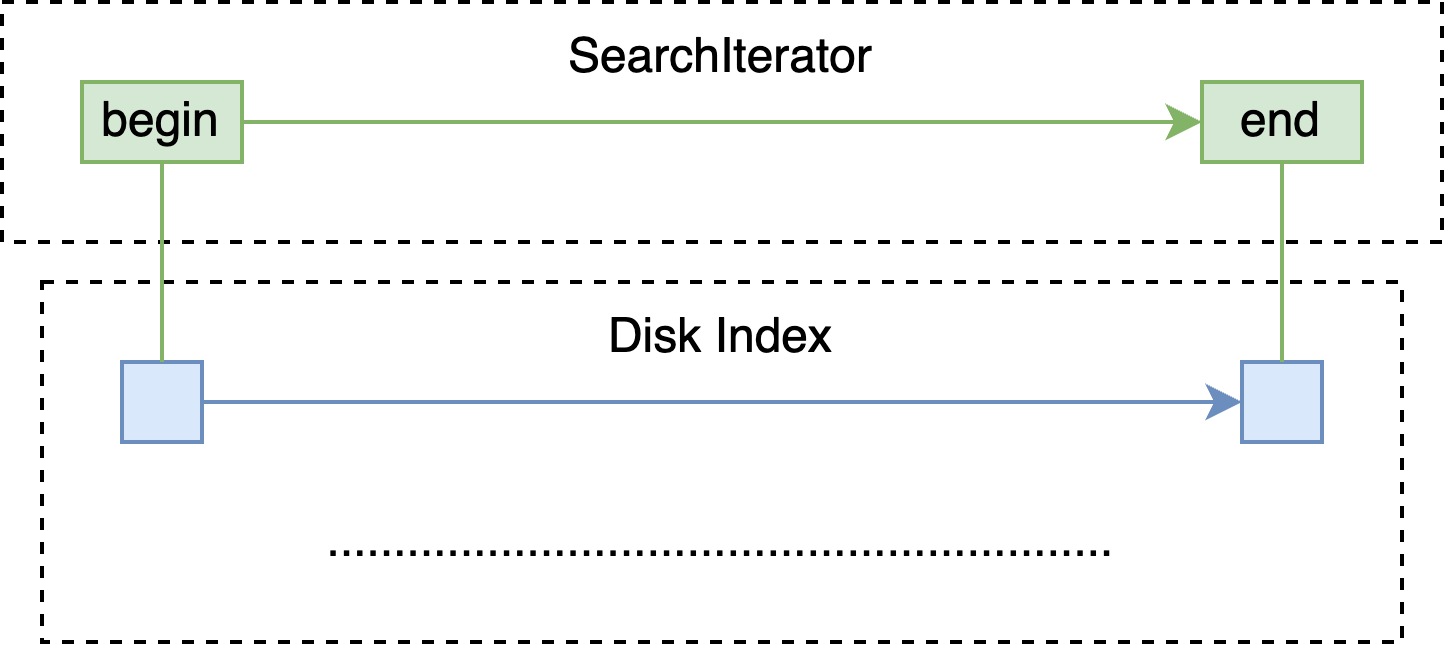
Disk Index
Disk index 的结构是多层跳表,查询即是在每层上定位区间,通过 offset 定位至下一层的区间内继续匹配。
WhiteListBlueprint
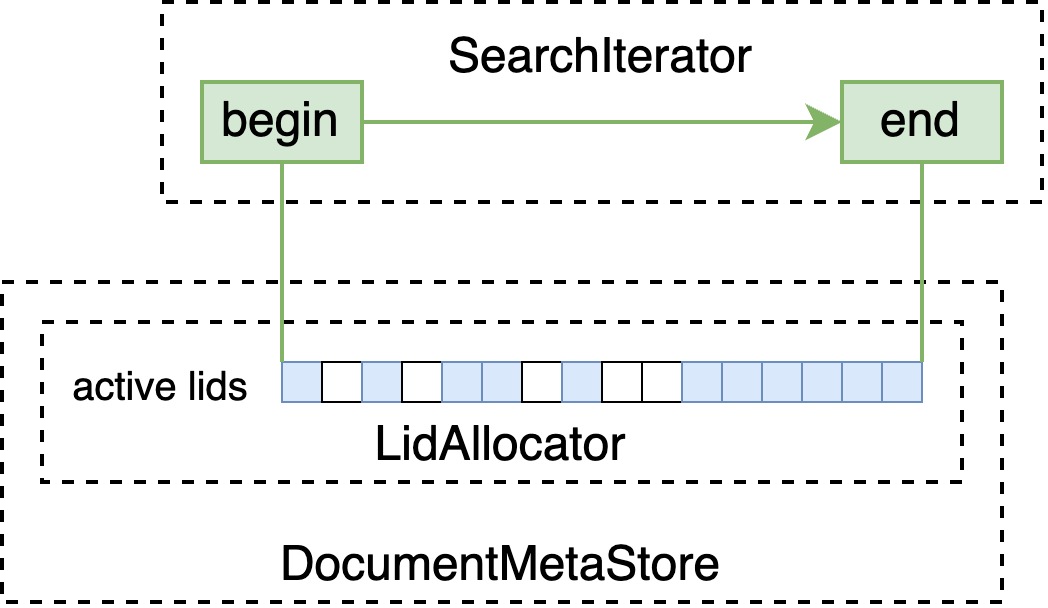
DocumentMetaStore 中以 BitVector 的形式存储正在使用的 local id(即下图中的 lid)空间,WhiteListBlueprint 会由此构建 BitVectorIterator ,筛选掉不存在的 doc id。
SourceBlenderBlueprint
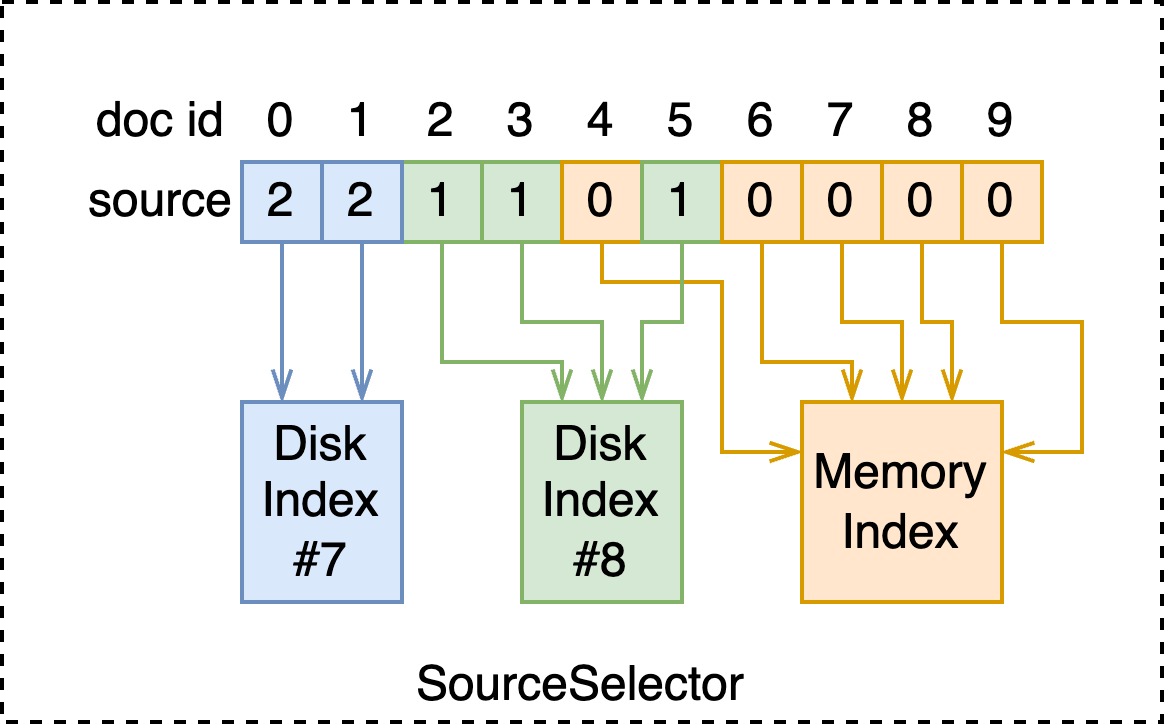
管理 index 时会存储如下图所示的 SourceSelector,其复用了 attribute 的数据结构。于是在 seek 每个 doc id 时,可以找到对应的 index。
void SourceBlenderSearch::doSeek(uint32_t docId) {
Source sourceId = this->sourceSelector->getSource(docId);
this->matchedChild = this->sources[sourceId];
if (this->matchedChild->seek(docId)) {
setDocId(docId);
}
}
以上是 non-strict 的版本,对于 strict 版本,需要快速地找到下一个 docId 所在的 index,实现较为复杂不展开介绍。
AndNotBlueprint
在这一节,我们暂时对这些常见的 IntermediateBlueprint 只做初级的介绍。诸如 Or、And、AndNot 的基本实现是简单的:
// non-strict
void OrLikeSearch::doSeek(uint32_t docId) {
for (uint32_t i = 0; i < children.size(); ++i) {
if (children[i]->seek(docId)) {
setDocId(docId);
return;
}
}
}
void AndSearchNoStrict::doSeek(uint32_t docId) {
for (uint32_t i = 0; i < children.size(); ++i) {
if (!children[i]->seek(docId)) {
return;
}
}
setDocId(docId);
}
void AndNotSearch::doSeek(uint32_t docId) {
if (!children[0]->seek(docId)) {
return; // not match in positive subtree
}
for (uint32_t i = 1; i < children.size(); ++i) {
if (children[i]->seek(docId)) {
return; // match in negative subtree
}
}
setDocId(docId);
}
多倒排合并
对于 prefix / range / fuzzy / regex 搜索来说,并不是每个 Blueprint 对应一个倒排表,Vespa 将这些逻辑全部封装在 PostingListSearchContext 中。在构建 SearchContext 检索到多个倒排表时,会将这些倒排表合并,合并的结果是数组或 bitvector。
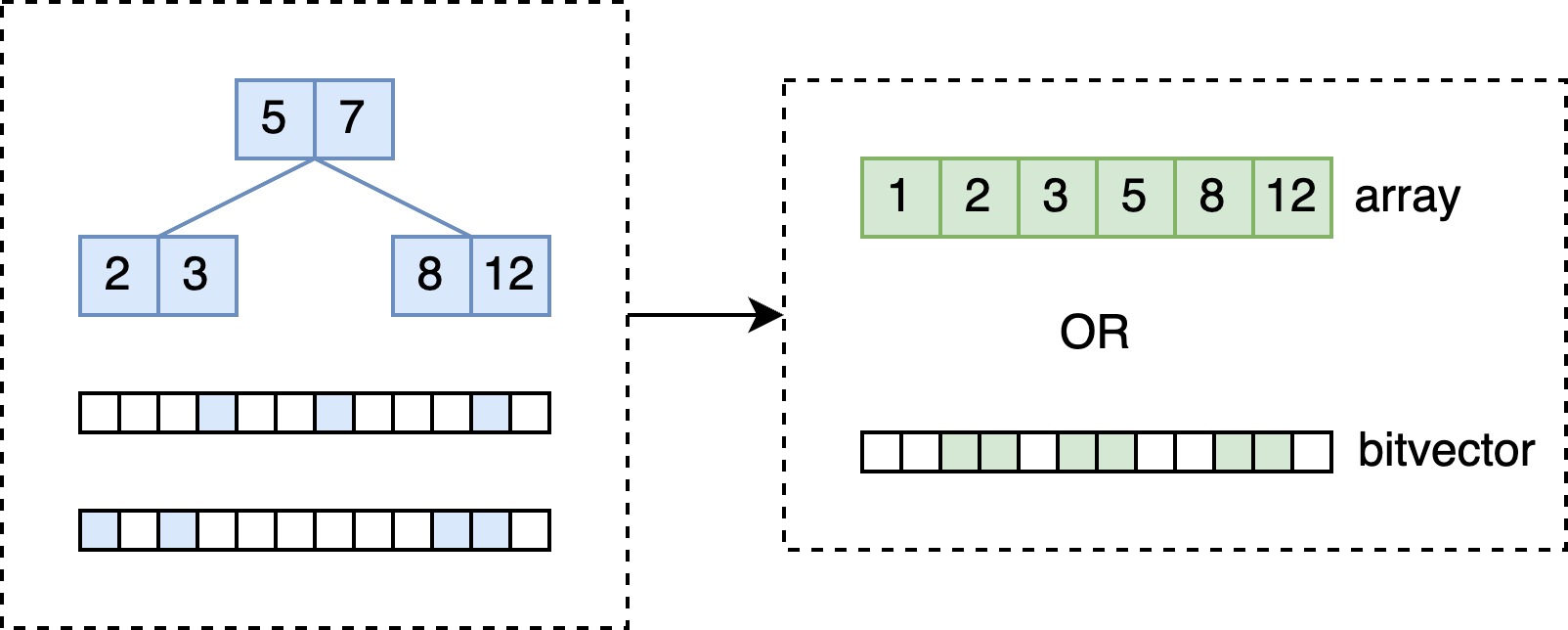
交并优化
显然上边的中间节点的实现的效率是很低的,尤其当子节点的数量过于膨胀时,这一节介绍 Vespa 中用到的常见的优化手段。
WeakAnd
如果被检索字段的相关性计算方式是简单的权重累加,可以使用此优化方案减少 or 和 and 下层检索的次数。weakAnd 在最大堆中维护一系列 score,以其中的最小分为阈值,剪枝掉一部分子 iterator 在不必要的 doc id 上进行的 seek。
具体实现较复杂, 建议在读过 Efficient Query Evaluation using a Two-Level Retrieval Process (PDF) 后查看具体代码 searchlib/src/vespa/searchlib/queryeval/wand/wand_parts.h。
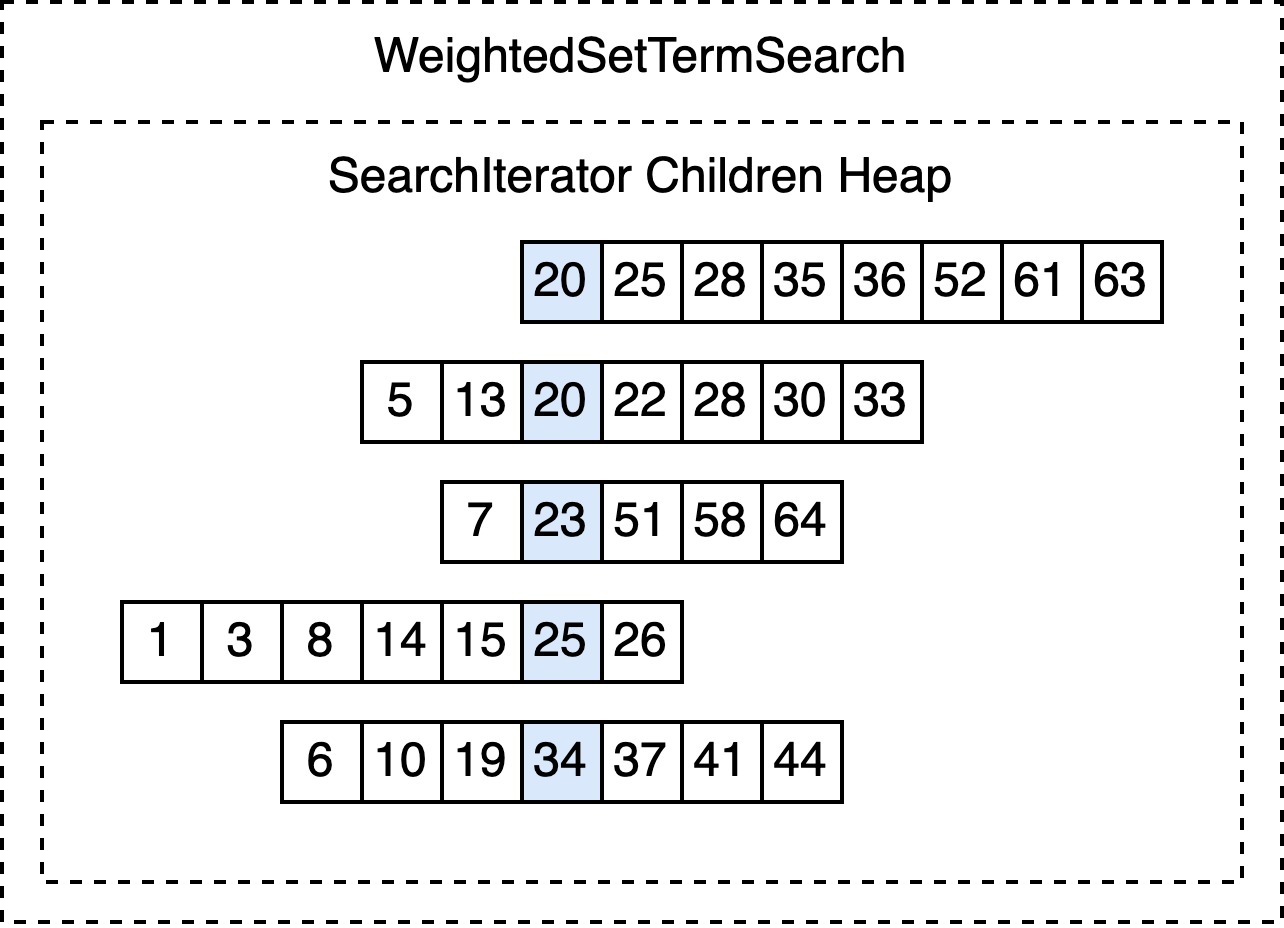
WeightedSetTermSearch / StrictHeapOrSearch / …
如前边所说,简单的中间节点 seek 的方式,就是遍历所有的子 iterator 逐个推进。Vespa 中广泛使用的一种优化是将它们按 docId 排序(数据结构往往是最小堆),在推进 docId 时可以减少调用子 iterator 的次数。
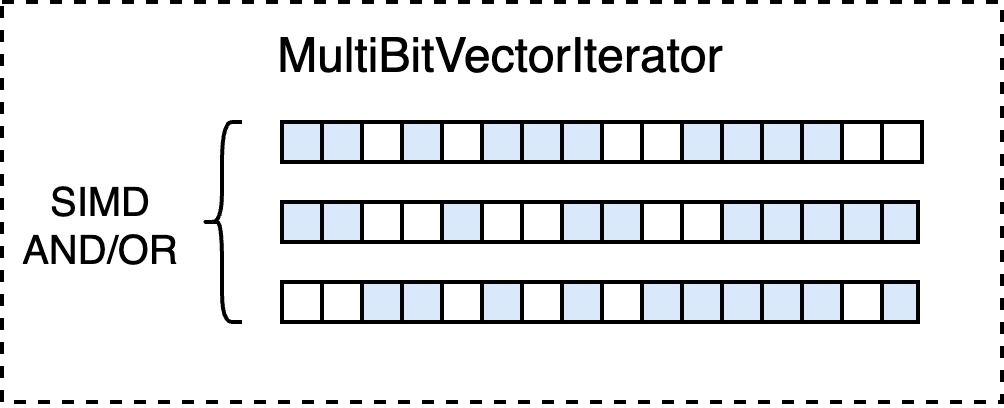
MultiBitVectorIterator
在构建完整的 SearchIterator 树后,最后一步的优化是寻找子节点均是 bitvector 实现的中间节点,于是可以批量地将这些 bitvector and/or,还可以利用 SIMD 加速这一过程。