KMP 算法回顾
记得系统学习 KMP 算法的时候是在大二的算法课上, 当时印象中掌握的是不错的, 不过时隔一年, 遇到 leetcode implement-strstr 一题需要用到 KMP 时, 居然理解上有些困难. 在这里回顾一下实现的重点.
搜索代码
int KmpSearch(char *s, char *p) {
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p);
while (i < sLen && j < pLen) {
// 如果j = -1, 或者当前字符匹配成功(即S[i] == P[j]), 都令i++, j++
if (j == -1 || s[i] == p[j]) {
i++;
j++;
} else {
// 如果j != -1, 且当前字符匹配失败(即S[i] != P[j]), 则令 i 不变, j = next[j]
// next[j]即为j所对应的next值
j = next[j];
}
}
if (j == pLen)
return i - j;
else
return -1;
}
next 数组
算法的核心在于, next 数组的意义
| 匹配字符 | 最大前缀后缀公共元素长度 |
|---|---|
| a | 0 |
| b | 0 |
| a | 1 |
| b | 2 |
next 数组值为相应值 - 1
| 匹配字符 | next |
|---|---|
| a | -1 |
| b | 0 |
| a | 0 |
| b | 1 |
计算 next 数组
- 如果对于值 k, 已有 $p_0 p_1, ..., p_{k-1} = p_{j-k} p_{j-k+1}, ..., p_{j-1}$, 相当于
next[j] = k. 这意味着,next[j] = k代表 p[j] 之前的模式串子串中, 有长度为 k 的相同前缀和后缀. 在 KMP 匹配中, 当模式串中 j 处的字符失配时, 下一步用 next[j] 处的字符继续跟文本串匹配, 相当于模式串向右移动 j - next[j] 位. - 若
p[k] == p[j], 则next[j+1] = next[j] + 1 = k + 1 - 若
p[k] != p[j]- 如果
p[next[k]] == p[j], 则next[j+1] = next[k] + 1 - 否则继续递归前缀索引
k = next[k], 而后重复此过程.
- 如果
最关键的问题在于为什么要递归前缀索引 k = next[k], 这一过程相当于模式的自我匹配. 不断地向前递归进行匹配, 直到成功.
由此有代码
void GetNext(char *p, int next[]) {
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1) {
// p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k]) {
++k;
++j;
next[j] = k;
} else {
k = next[k];
}
}
}
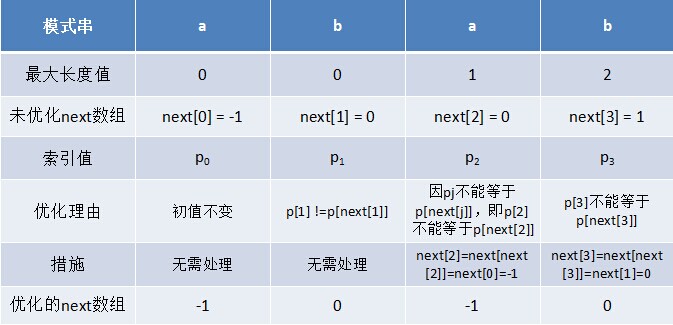
不过这个代码的问题在于, 当匹配失败时, 递归到 p[next[k]] 时, p[next[k]] 和 p[k] 仍很有可能相同, 如下图
| 匹配字符 | j | next |
|---|---|---|
| a | 0 | -1 |
| b | 1 | 0 |
| c | 2 | 0 |
| d | 3 | 0 |
| a | 4 | 0 |
| b | 5 | 1 |
| d | 6 | 2 |
可见, p[5] == p[next[5]], p[4] == p[next[4]].
由此可优化, 当相等时, 可令 next[j] = next[next[j]], 减少了在 KMP 搜索时的递归.
void GetNextval(char *p, int next[]) {
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1) {
// p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k]) {
++j;
++k;
// 较之前next数组求法,改动在下面4行
if (p[j] != p[k])
next[j] = k; //之前只有这一行
else
// 因为不能出现p[j] = p[next[j]],所以当出现时需要继续递归
// k = next[k] = next[next[k]]
next[j] = next[k];
} else {
k = next[k];
}
}
}
以上是对 从头到尾彻底理解KMP 的自我理解.