Vespa Matching - 自顶向下
本文是基于基于之前的两篇博客 Vespa 索引结构实现、Vespa 索引检索实现 重新梳理的、自上而下的、更易懂的 Vespa Matching 的介绍,用于本人分享。
Vespa 是由 Yahoo 开发的高性能大数据检索引擎,专为大规模低延迟的场景设计,支持文本、结构化数据、向量的检索。
Blog Documentation DeepWiki GitHub Slack
Overview
Components

-
Admin/config cluster
-
cluster controller 集群状态管理
-
configserver 基于内置 zookeeper
-
slobrok 服务(组件 / route)发现
-
monitoring metrics
-
-
Stateless Java container cluster
-
Searching
- [Request/Response processing](Request/Response processing)
- Search chain
-
Indexing
-
-
Content cluster
- Distributor (Bucket management)
- Searchnode
Searching Process

参照上图,对于一次搜索请求,在最简单的情况下
- 请求发送至无状态的 QRS (Query Rewrite Service) 集群后:
- 由 YQL(类似于 SQL)或其它形式的请求体,构造 query tree;
- 使用负载均衡策略,发送 query 请求至某个 group(或称一行、一个副本,含全量文档)全部 node 的 searchnode; 一个 node 通常等价于 k8s 的一个 pod,包含两个组件 distributor 和 searchnode; distributor 不会参与搜索流程,它只与 document 相关请求有关;
- 每个 searchnode 收到 query 请求后:
- 从 query tree 构建执行计划;
- 多线程地一边匹配一边进行第一阶段的打分;
- 取第一阶段匹配/打分的 top k 结果,进行第二阶段打分;
- 排序;
- 返回 docIds, sortData 等;
- QRS 收到所有 response 后:
- 归并;
- global-phase 打分;
- 排序;
- 发送 fetch 请求至原 searchnode,填充字段、分数及其它调试信息;
- End

本文以下内容重点关注的内容在:
Vespa
- Distributed System
- Configuration
- Consistency Model
- Distribution / Bucket Algorithm
- Components
- Container
- Content Node
- Distributor
- Searchnode
- Indexing
- Searching
- Matching
- Ranking
- Summary
Matching
Inverted Index
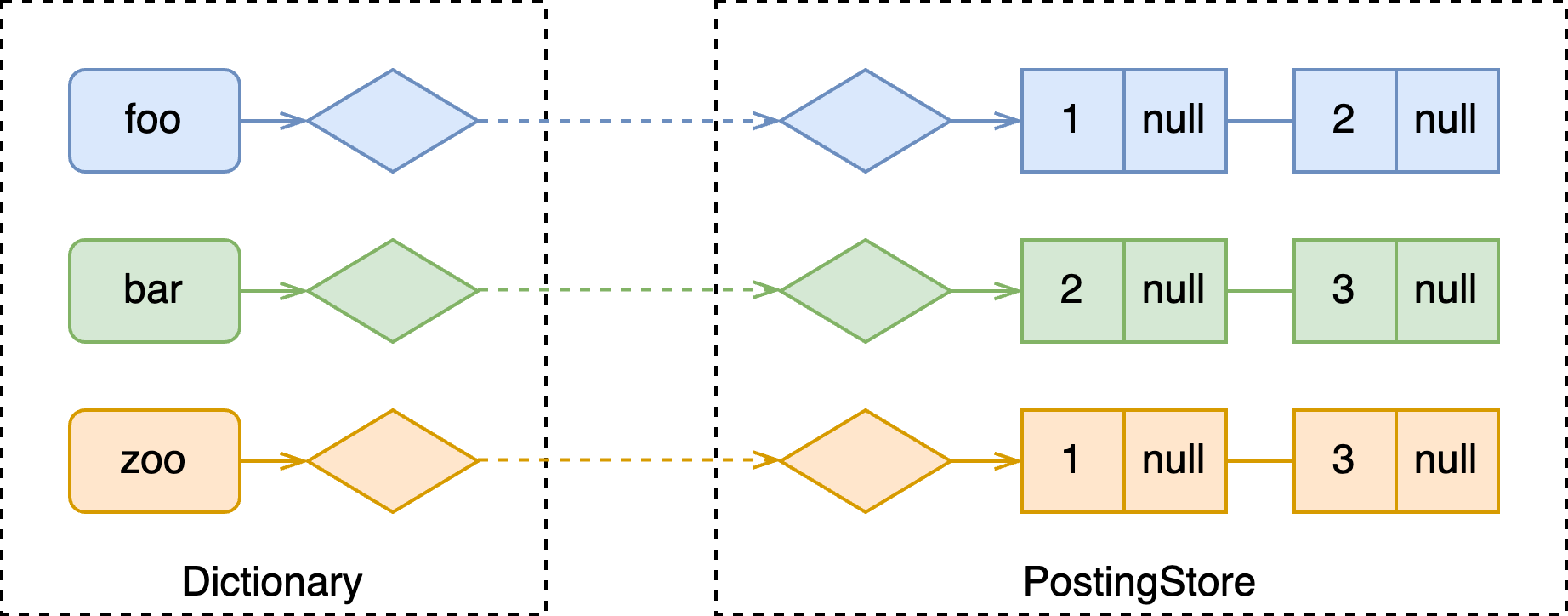
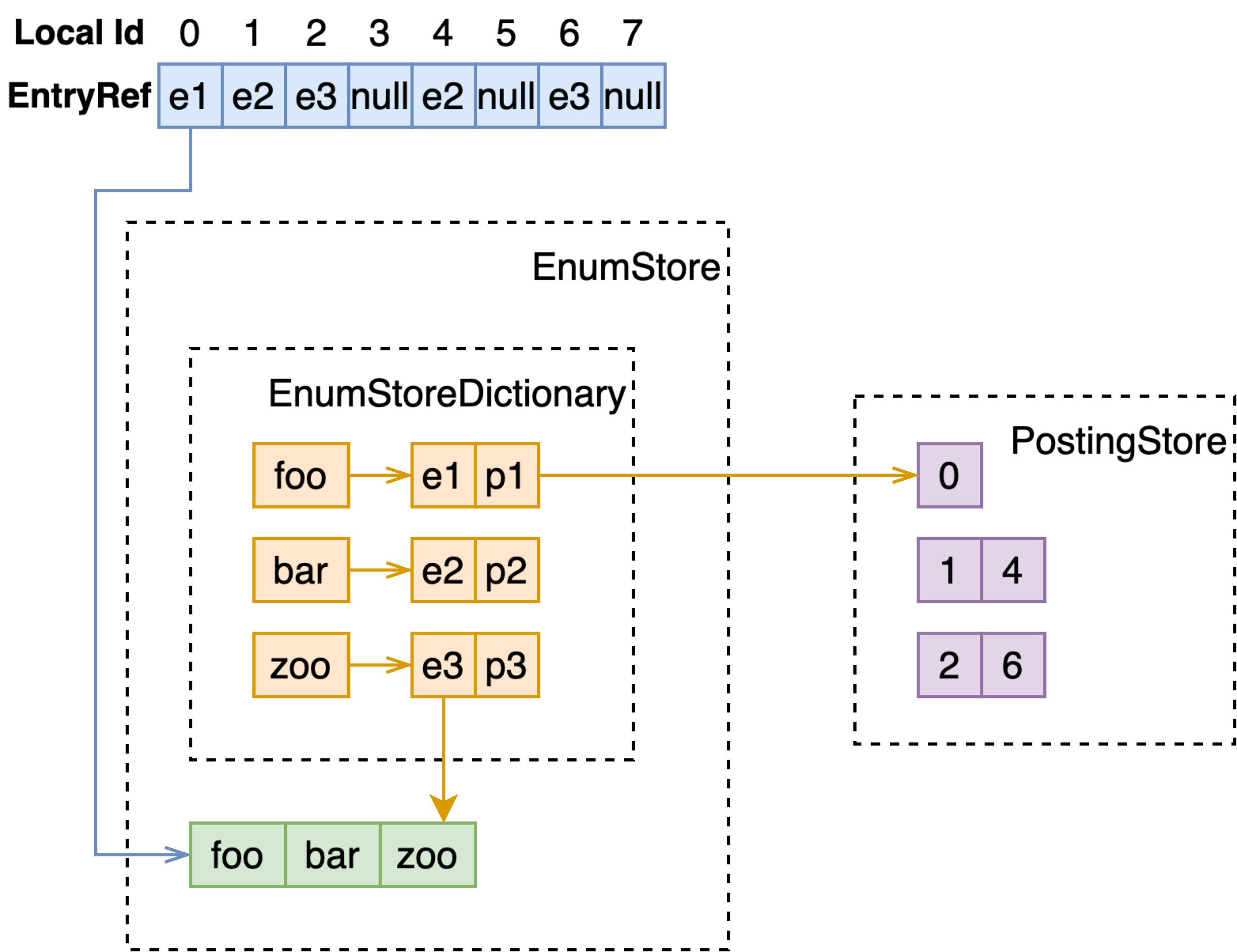
补课:一般来说,倒排索引都包含两部分:词典(dictionary)和拉链(posting list)。
- 词典以 term 为 key,value 为指向其对应倒排表的 id;
- 拉链存储了一系列拥有该 term 的文档 id; 在 Vespa 中,以 list<key-value> 的形式表示,其中 key 为 docId,value 为 null、权重等信息。
举个例子,假设引擎中现在存储多篇文档,如下。
[
{"0": "foo bar"},
{"1": "bar zoo"},
{"2": "foo zoo"}
]
会构建如下所示的倒排索引:
Execution Plan
上一节中已经提到,输入的 YQL 会在 QRS 上转换为 query tree,后在 searchnode 上转换为执行计划。如下图所示(此处简要看下,下边会详细展开):
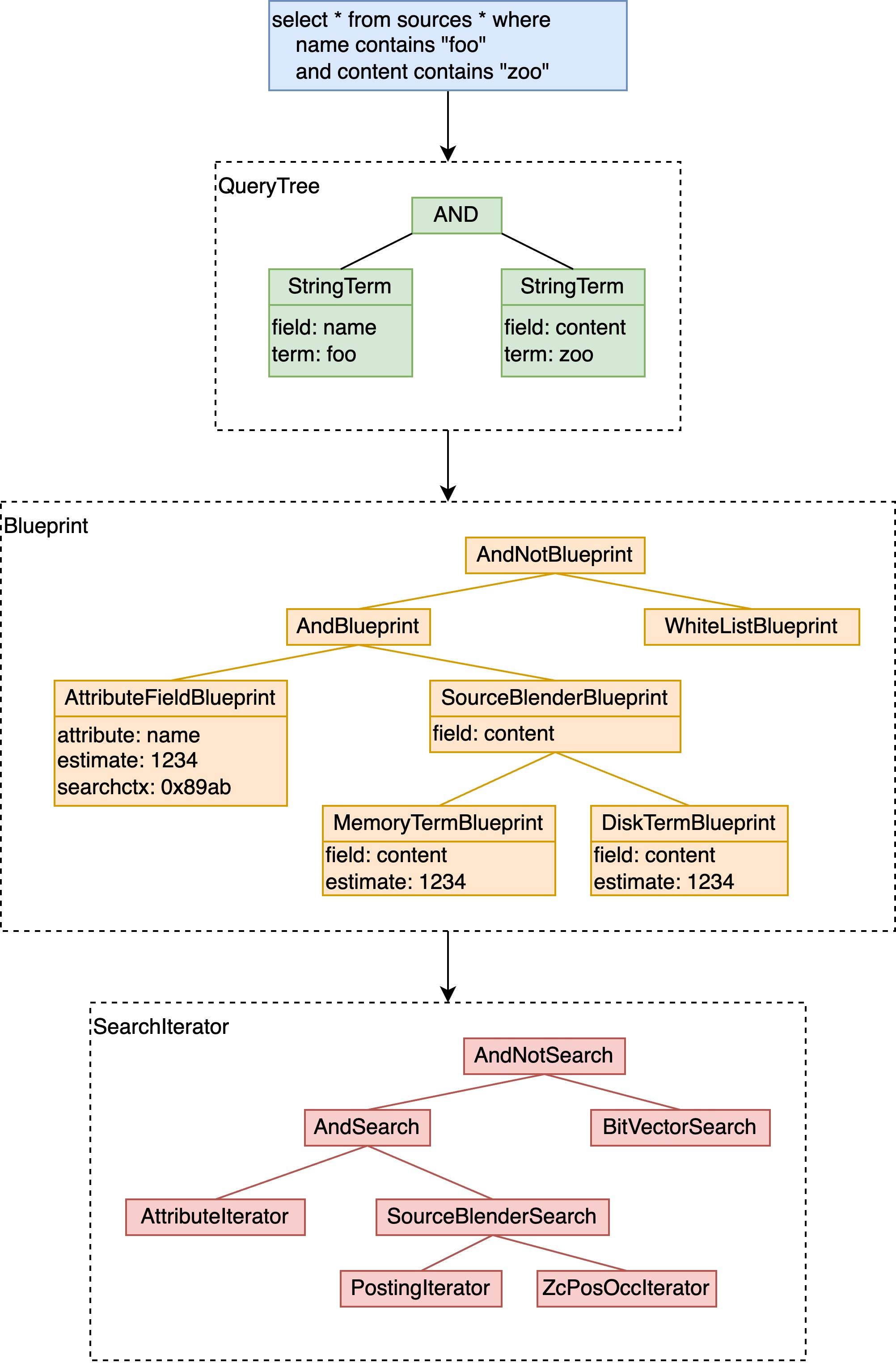
- YQL => QueryTree:将用户输入转化为便于引擎处理的语法树,通常会进行优化,减少树的深度;
- QueryTree => Blueprint:即所谓的逻辑执行计划,若检索的字段有索引,此时已经定位到其拉链(posting list),于是可以确定每个叶子/中间节点 blueprint 的预估文档数量,进行进一步地剪枝、执行顺序优化(含向量检索的 pre/post filter);
- Blueprint => SearchIterator:即物理执行计划,定义了在内存/磁盘上的流程。
Match Loop
更详细地,在写入文档时,每个 searchnode 会将其全局 id(global id)映射为从 0 开始连续的 id、称为 local id。
基于 Blueprint 会构建若干 SearchIterator 树用于每个线程使用,于是可以将 local id 空间按线程数分为若干段,每颗 SearchIterator 树在这段 local id 空间上从低位至高位匹配,简化代码如下:
uint32_t MatchThread::inner_match_loop(Context &context, MatchTools &tools, DocidRange &docid_range) {
SearchIterator *iterator = &tools.search();
search->initRange(docid_range.begin, docid_range.end); // reset the state & find the first docId
while (docId < docid_range.end) {
if (do_rank) {
search->unpack(docId); // unpack features needed by ranking
context.rankHit(docId); // first-phase ranking using another ranking Blueprint tree
} else {
context.addHit(docId);
}
docId = search->seekFirst(docId + 1); // linearly find the next docId
}
return docId;
}
seekFirst 的实现可以分为如下几种情况:
- 叶子节点
- 无倒排:线性地逐个取出文档,判断是否匹配;
- 有倒排:在拉链上读出下一个 docId;
- 中间节点:递归地推动子 SearchIterator 向前匹配,对于 And / Or / AndNot 等均有不同的实现。
Optimization: strict
为简化后续代码,我们先引入 vespa 的一项优化:strict。
上述 seekFirst 提到检索就是线性地在 docId 空间或倒排表上前进。显然可以只让其中一部分 SearchIterator 线性地前进(即所谓 strict),另一部分只探测这些 docId 是否匹配,以简化后的 SearchIteratorBitVector 代码为例:
// strict
void BitVectorIteratorStrictT::doSeek(uint32_t docId) {
docId = getNextBit(docId);
this->setDocId(docId);
}
// non-strict
void BitVectorIteratorT::doSeek(uint32_t docId) {
if (isSet(docId)) {
this->setDocId(docId);
}
}
- strict:
getNextBit向后探测 bit,直至找到下一个为 1 的位置; - non-strict:直接判断该 docId 处的 bit 是否为 1。
在构建 SearchIterator 树前,会计算 strict 或 non-strict 的预期开销,选择开销更低的实现构造,实现见searchlib/src/vespa/searchlib/queryeval/flow.h。
Intermediate Blueprints
自顶向下地,我们在 Blueprint 层面上从中间节点开始讲起。
And / Or / AndNot
在引入 strict 概念后,可以看到 non-strict 时,中间 Blueprint 的代码比较简单,即遍历子树判断 docId 是否匹配。
// non-strict
void OrLikeSearch::doSeek(uint32_t docId) {
for (uint32_t i = 0; i < children.size(); ++i) {
if (children[i]->seek(docId)) {
setDocId(docId);
return;
}
}
}
void AndSearchNoStrict::doSeek(uint32_t docId) {
for (uint32_t i = 0; i < children.size(); ++i) {
if (!children[i]->seek(docId)) {
return;
}
}
setDocId(docId);
}
void AndNotSearch::doSeek(uint32_t docId) {
if (!children[0]->seek(docId)) {
return; // not match in positive subtree
}
for (uint32_t i = 1; i < children.size(); ++i) {
if (children[i]->seek(docId)) {
return; // match in negative subtree
}
}
setDocId(docId);
}
而对于 strict 情况,暴力循环性能很差,vespa 引入如下几种优化:
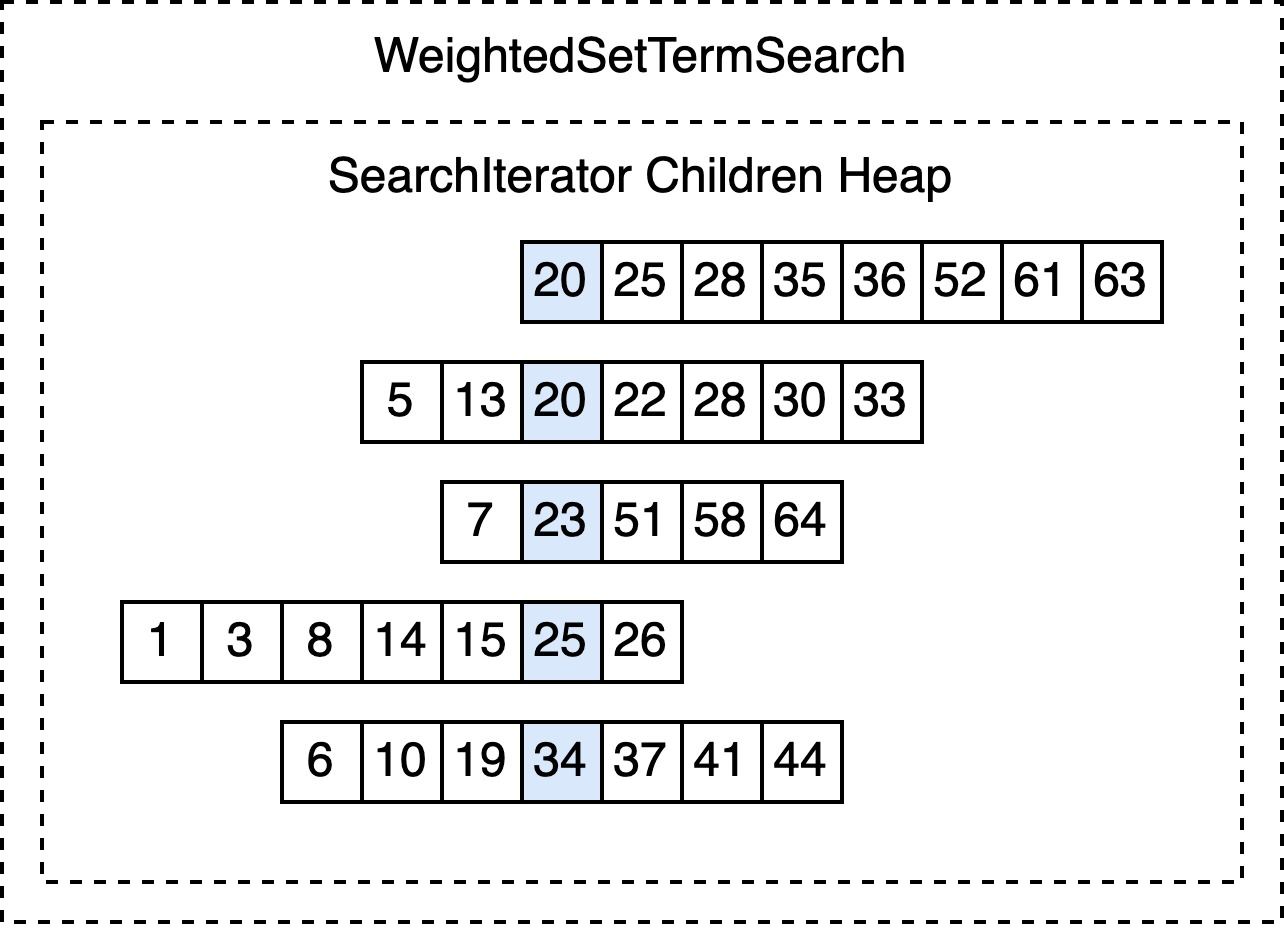
Optimization: heap
将所有子 SearchIterator 按照其当前 docId 排序(数据结构大部分情况为最小堆),于是在推进儿子节点时,可以减少调用 seek 次数:
Optimization: weakAnd
weakAnd 算子是更高效率的 OR 中间节点实现,如果被检索字段的相关性计算方式是简单的权重相加,那么可以使用该方式减少下层检索次数。
当一个 Or SearchIterator 包含多个子节点时、尤其当这些子节点的并集覆盖了大量文档时,如上图所示的优化并不能从数量级上减少检索次数。
WAND 算法会借助索引中写入的每个拉链可以贡献的分数最大值(如 bm25 等),亦即每个子节点可以贡献的最大分数,通过堆的方式,维护一个 threshold 值,只有当某个文档存在于的多个拉链的分数最大值之和大于 threshold 时,才会实际进行检索与分数计算。
通过以上的算法,在理想状态下可以减少 90% 以上的计算次数,在实际线上也有非常显著的收益。
具体原理见论文:Efficient Query Evaluation using a Two-Level Retrieval Process (PDF)
ElasticSearch 也有类似实现:https://www.elastic.co/blog/faster-retrieval-of-top-hits-in-elasticsearch-with-block-max-wand
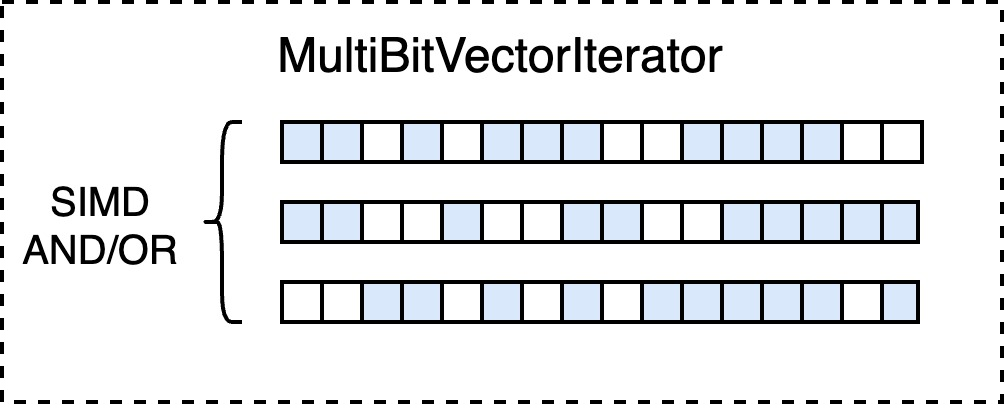
Optimization: SIMD
在构建完整的 SearchIterator 树后,最后一步的优化是寻找子节点均为 bitvector 实现(取决于索引结构)的中间节点,于是可以利用 SIMD 加速 and / or / multi 的运算。
Term
最后,我们来到具体的最底层的 term 检索:
select * from sources * where name contains "foo"
该 YQL 语句要检索 name 字段包含 foo 的文档,根据 name 字段配置的索引方式,需要分类讨论。
Vespa 提供了以下几种存储/索引方式:
-
Attribute:内存中列式存储,不分词,结构化数据
- 无倒排
- 有倒排:
attribute: fast-search
-
Index:分词,有倒排,内存+磁盘混合索引
-
documentstore:类 LSM 树的行存
来到这一节,需要再次明确,Vespa 在单机上都是映射为 local id 后,再进行存储,Blueprint 于是可以在连续的 local id 空间上匹配。以 local id 为数组序号,Vespa 可以在一个数组中,密集地放下某个字段所有文档的值(最简单的情况下)。当然随着文档的过期删除,Vespa 会在后台自动地压缩这片空间。
Attribute
Attribute 在内存中的列式存储便于:
- 在 fetch 阶段更快地获取每个 doc 这一 field 的值;
- Grouping / ranking / sorting 都依赖于 attribute 加速;
- 可以选择构建倒排,用于结构化数据的匹配。
Plain
对于单值、定长(比如数字)、无倒排,Vespa 的存储结构只需简单的 RCU vector 即可:
单机 10M 文档,只需要 10M x 4 Byte = 40 MiB。

对于单值、不定长、无倒排,变长的字符串需要存储在额外的 EnumStore 中:
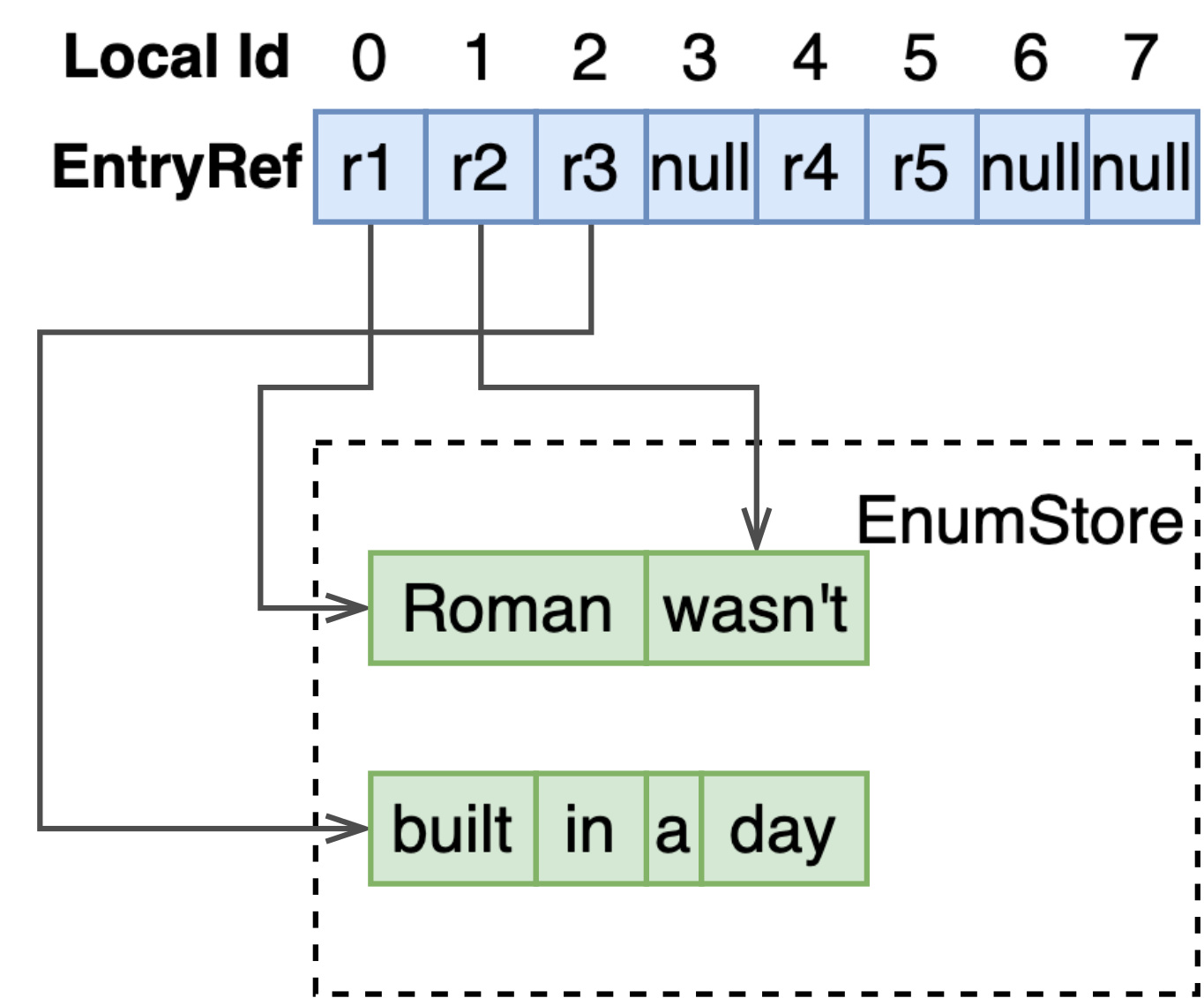
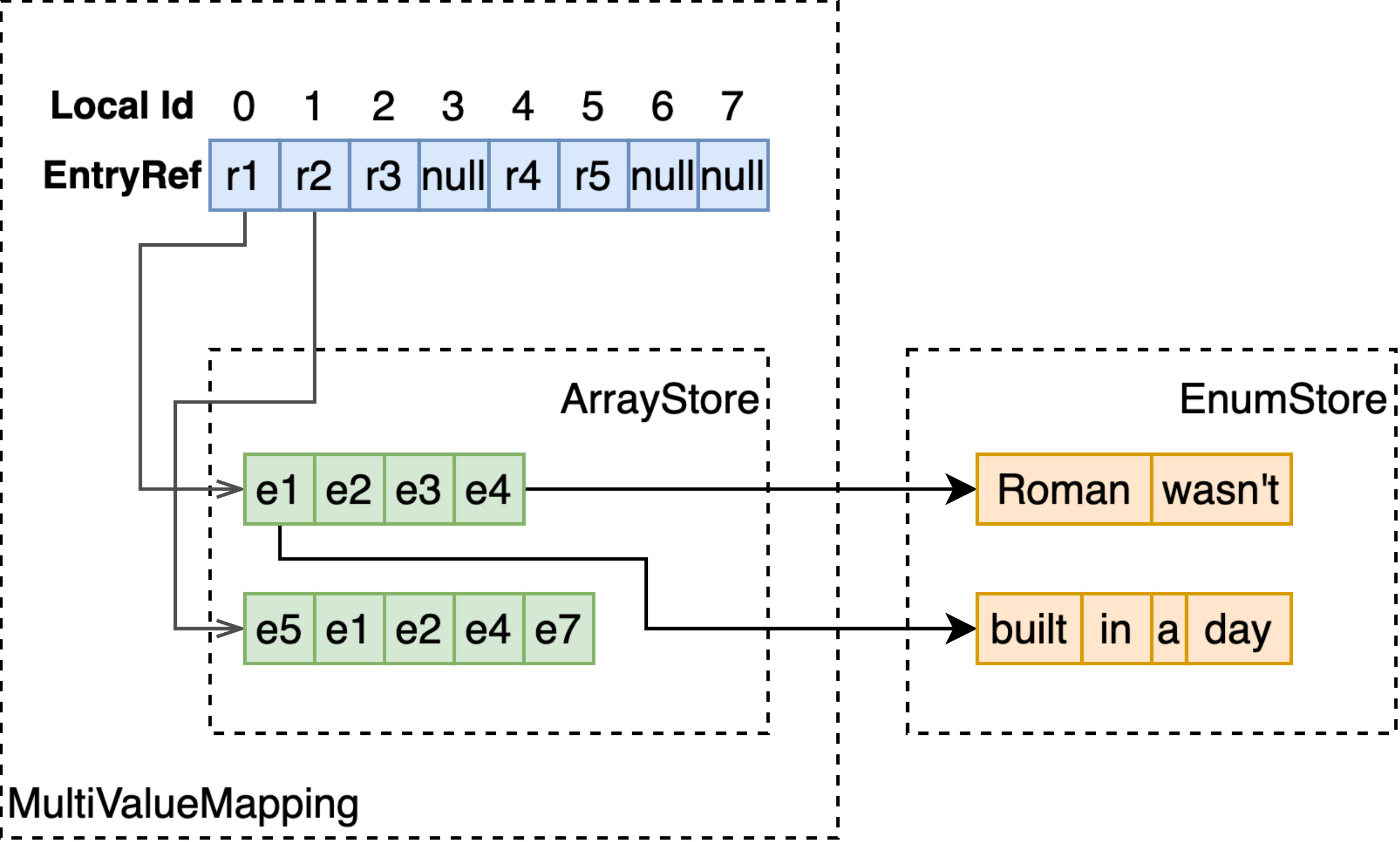
多值、不定长、无倒排,每个 docId 先指向在 ArrayStore 中存储的数组,再指向 EnumStore 中的变长值。
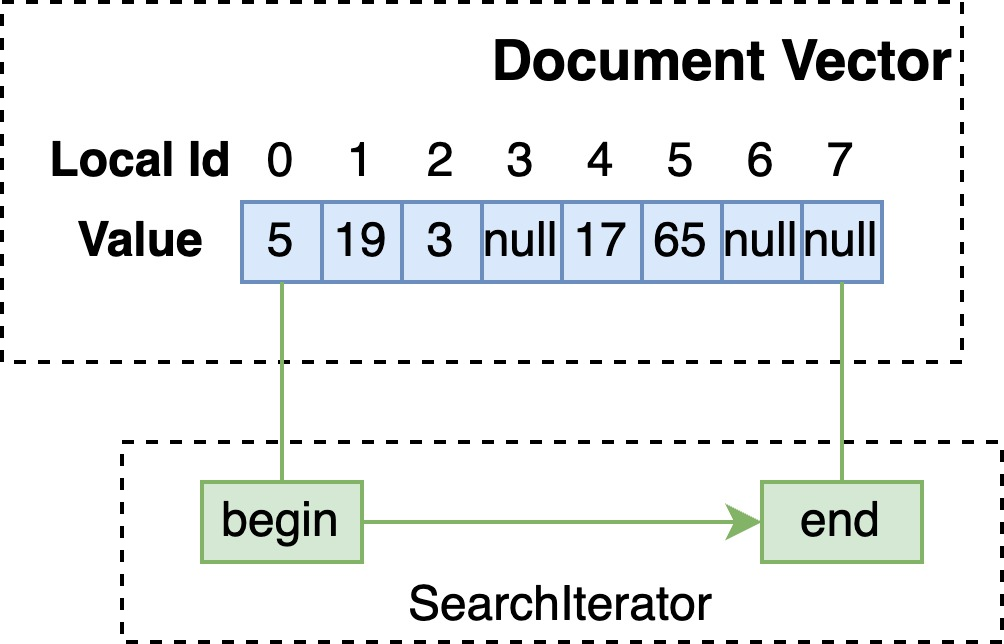
于是,当 SearchIterator 在该字段上检索 seek 至某个 docId 后,取出其值进行匹配即可:
简单的代码如下:
// single value
int32_t find(DocId docId, int32_t elemId) const {
T v = _enum_store.get_value(_enum_indices[docId].load_acquire());
return this->match(v) ? 0 : -1;
}
// multi value
int32_t find(DocId doc, int32_t elemId) const {
auto indices(_mv_mapping_read_view.get(doc));
for (uint32_t i(elemId); i < indices.size(); i++) {
T v = _enum_store.get_value(multivalue::get_value_ref(indices[i]).load_acquire());
if (this->match(v)) {
return i;
}
}
return -1;
}
FastSearch
当有倒排时,在构建 Blueprint 时,既可通过词典(dictionary)定位至拉链(posting list),SearchIterator 在拉链上线性地推进。
void AttributePostingListIteratorT::doSeek(uint32_t docId) {
// _iterator is on the posting list
_iterator.linearSeek(docId);
if (_iterator.valid()) {
setDocId(_iterator.getKey());
} else {
setAtEnd();
}
}
Index
-
Index 是 Vespa 中另一主要的索引方式。与 attribute 不同,使用 index 索引方式的字段,会经历 tokenizing、normalizing、stemming,即会把一整段文字进行分词归一化等操作,这样的索引方式显然是为像网页文本搜索服务的;
-
index 只会构建倒排索引,不会额外存储全量的数据。且倒排索引不会全部放在内存中,会有相当一部分存在于磁盘上。当文档写入时,会先更新内存中的 memory index,memory index 会定期写入磁盘(flush),然后和已有的磁盘上的 disk index 合并(fusion)。当检索该字段时,需要同时查询 memory index 和 disk index 后合并结果;
-
Disk index 是不可更改的,当要删除的文档在 disk index 上时,如果不借助额外的数据结构,检索时会搜到该文档。Vespa 提供的方案是,在原始构建的 Blueprint 上层,AndNot 一个 WhiteListBlueprint,WhiteListBlueprint 会读取 document store 中的 doc id bitvector,筛选已经被删除的文档。
于是,一个简单的 term query,构建的 Blueprint 会变成:
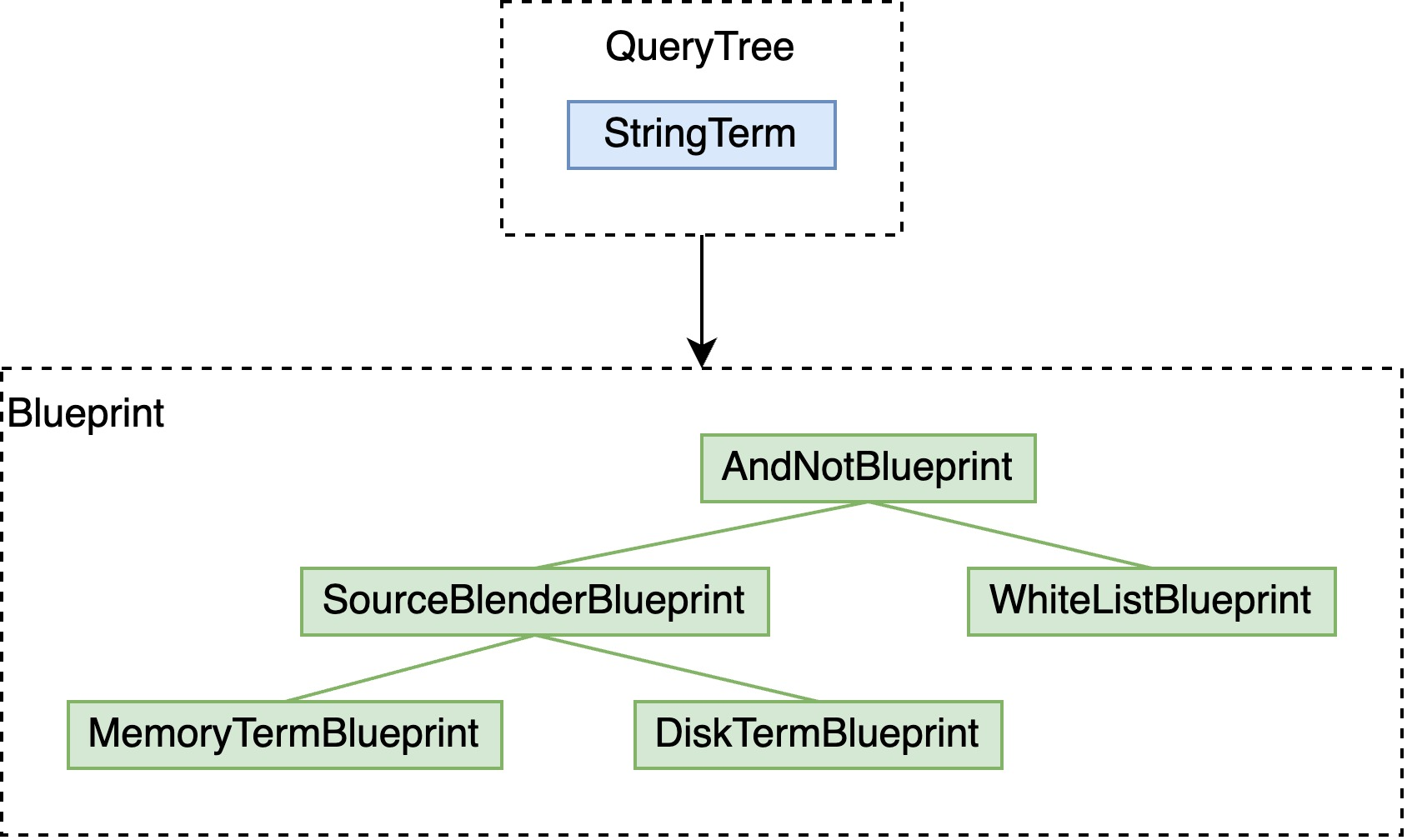
下边具体展开每项阐述。
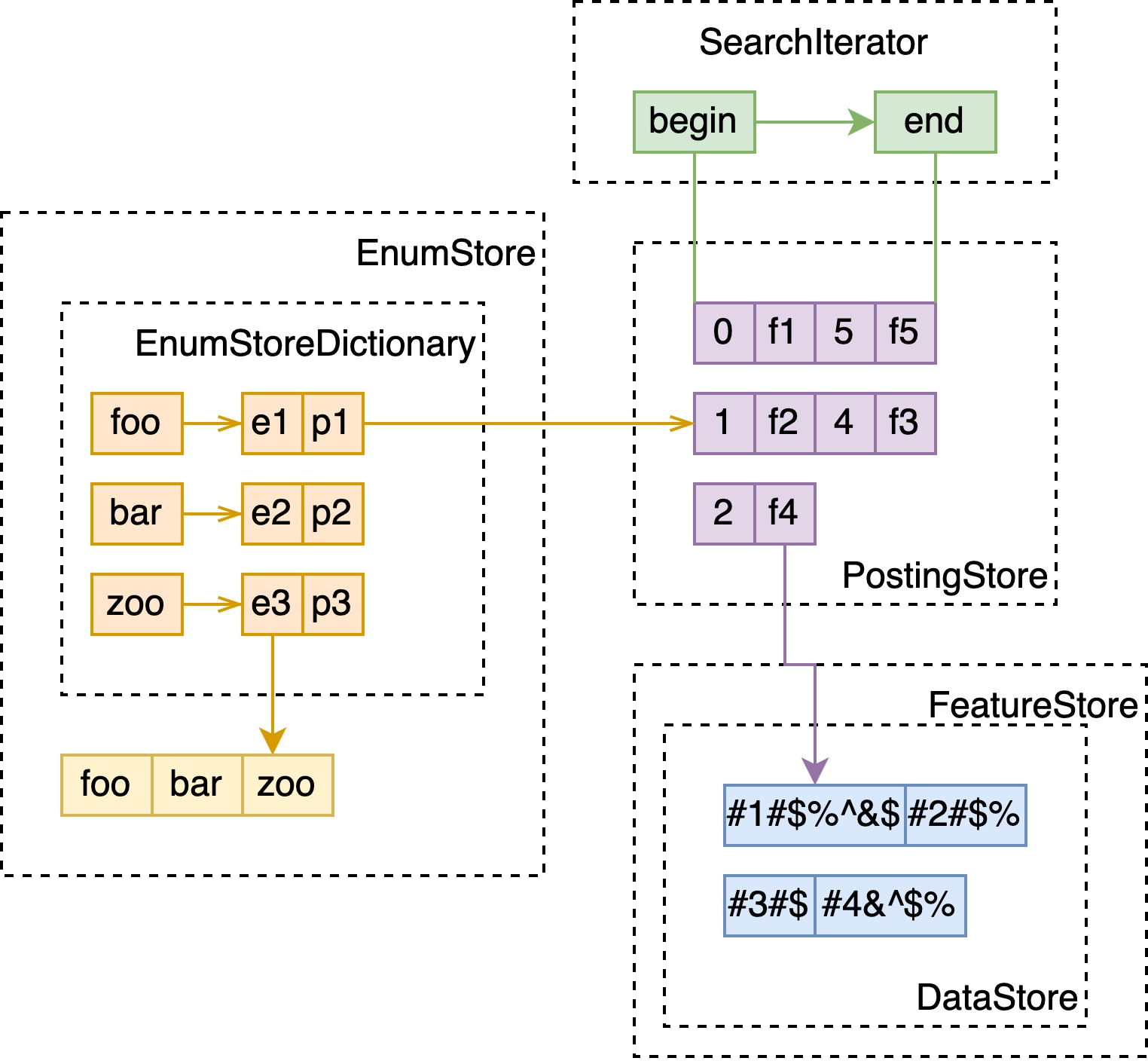
Memory Index
这里与 attribute x fast-search 几乎一致,不同的是:
- 不需要另外存储全量数据,于是没有 DocumentVector 和 MultiValueMapping;
- 经过 tokenizing 的文本,会带有如词频、位置等信息,用于之后的 bm25、nativeRank 计算,故会有额外的 FeatureStore 数据结构存储这些特征信息,在 PostingStore 中成对存储了 docId 和指向 FeatureStore 的 EntryRef。
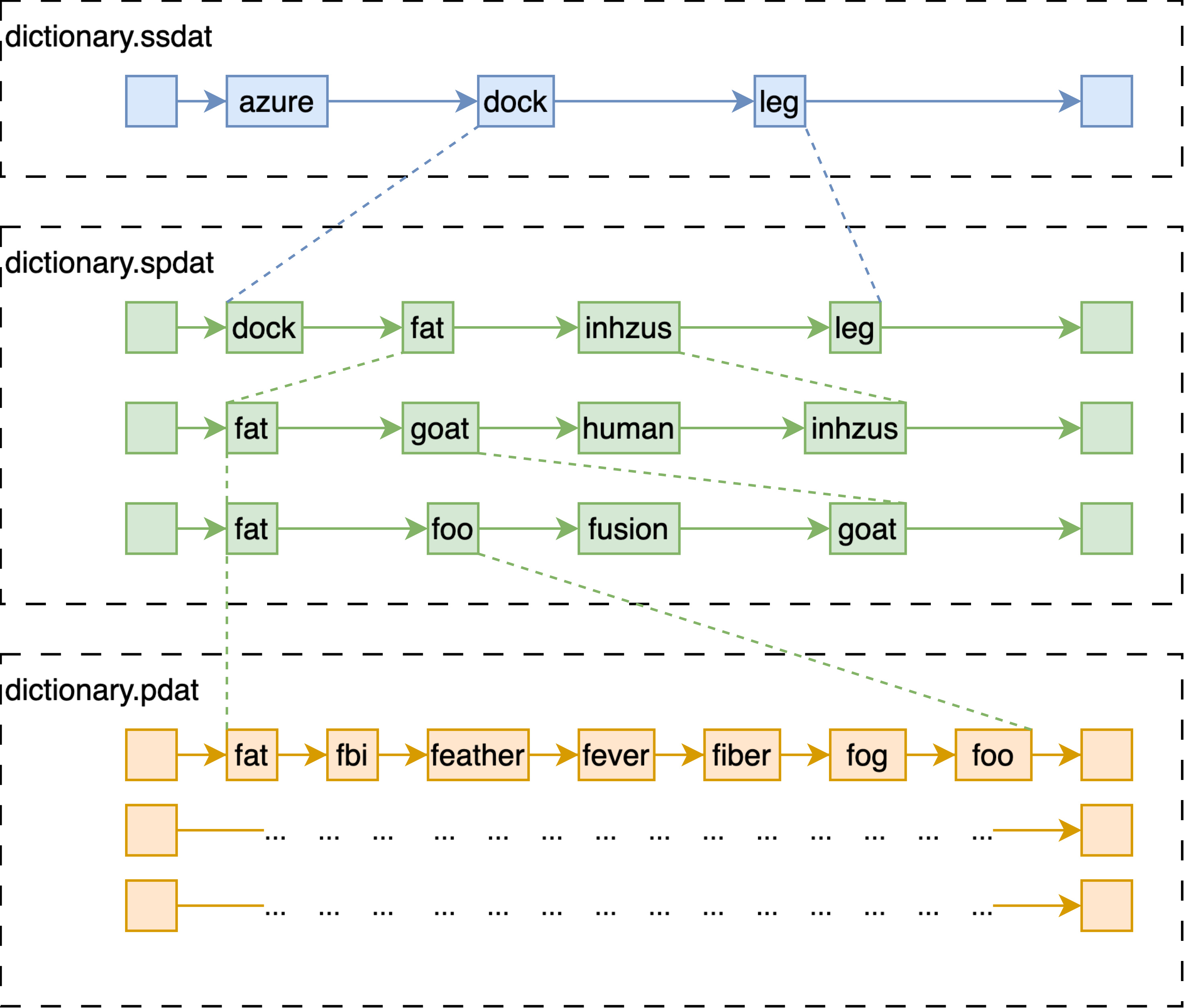
Disk Index
- Disk index 在磁盘中的索引结构等价于七层跳表;
- 跳表的最上层,文件名以 ssdat 结尾,会被全量加载至内存中;
- 中间三层和下边三层,分别存储在两个文件中,以 spdat 和 pdat 结尾;
- Disk index 的拉链 posting list 被压缩后存在以 dat.compressed 结尾的文件中;
- 另外还保存了精简版本的 bitvector 形式的索引,在不需要提取具体特征时使用,两个文件分别以 bdat 和 idx 结尾。
注意到事实上,尽管这些文件都在磁盘上,在内存足够的情况下,在我们内部的版本中,往往会 mmap 分配一块匿名内存,然后将这些文件全部映射至内存中。官方的版本提供了 populate 这一选项,也就是在 mmap 文件至内存时,尽量减少 page fault 的发生。
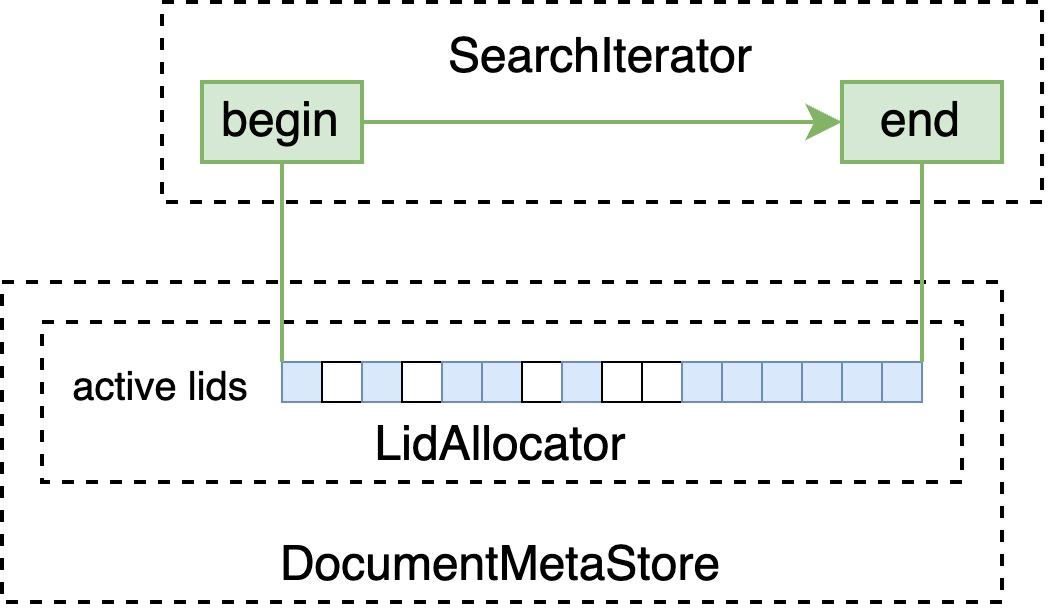
WhiteListBlueprint
DocumentMetaStore 中以 BitVector 的形式存储正在使用的 local id(即下图中的 lid)空间,WhiteListBlueprint 会由此构建 BitVectorIterator ,筛选掉不存在的 doc id。
SourceBlenderBlueprint
管理 index 时会存储如下图所示的 SourceSelector,其复用了 attribute 的数据结构。于是在 seek 每个 doc id 时,可以找到对应的 index。
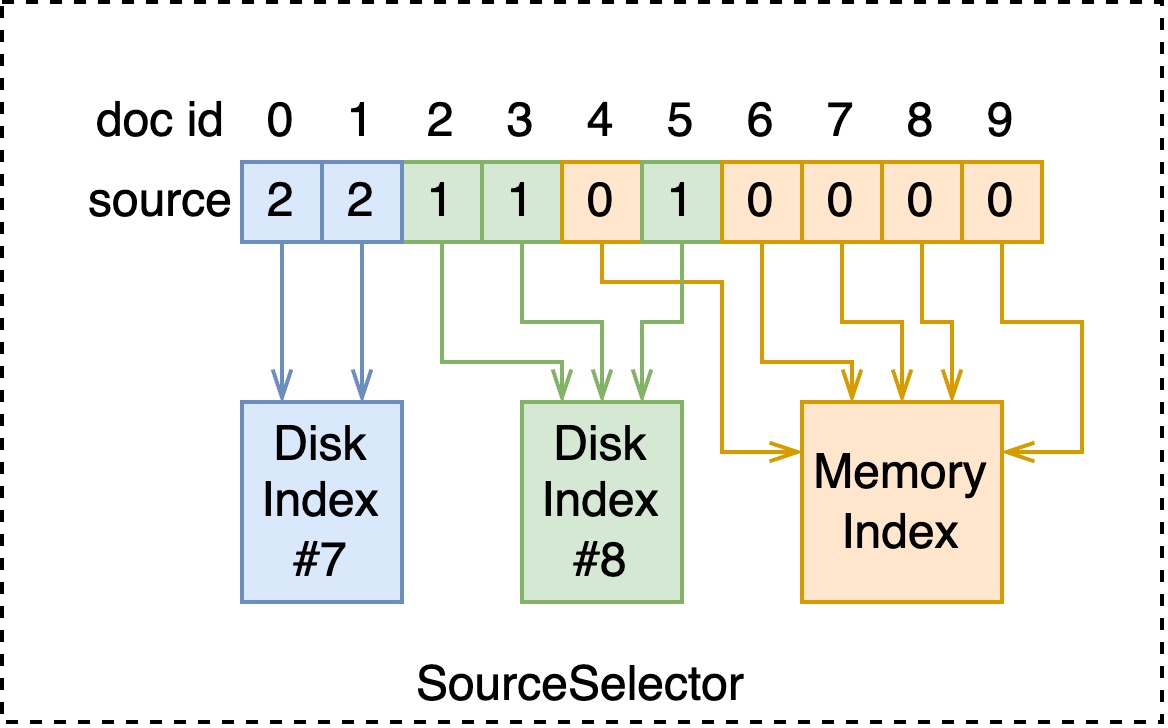
// non-strict
void SourceBlenderSearch::doSeek(uint32_t docId) {
Source sourceId = this->sourceSelector->getSource(docId);
this->matchedChild = this->sources[sourceId];
if (this->matchedChild->seek(docId)) {
setDocId(docId);
}
}
Data Structure
Posting List
最通常状态下,倒排表以如上图中 B-Tree 的形式组织:
-
从文档写入的角度来讲,增删的复杂度都相对较低;
-
从查询的角度来讲,B-Tree 是可遍历的,且对内存访问较友好;
-
值得注意的,插入或删除一系列文档时,若完全重新构建的开销更低,则不会选择直接插入;公式:
buildCost = treeSize * 2 + additionSize \\
modifyCost = (log_2(treeSize + additionSize) + 1) * (additionSize + removeSize)
当拉链长度小于 8 时,B-Tree 会被替代为简单的数组,可以在几乎不影响查询性能的情况下,减少写入的开销。
当长度大于 max(128, 文档数 >> 6) 时,会在 B-Tree 外构建 BitVector:
- 优点:极大地加速了匹配速度;
- 缺点:只能确定是否包含某个文档,无额外空间容纳每个文档额外的数据,如权重等这些在相关性分数计算时需要的数据;
- 由于以上的缺点,只有在 query 不参与相关性分数计算、只用做过滤时,才能使用 BitVector 进行高效率地匹配;
- 当然如果在配置中声明该字段就只参与过滤,便不会构建 B-Tree,提高写入性能。
DataStore
DataStore 是 Vespa 中的通用容器,向其中存储一段数据会得到一个唯一 id,之后可以通过这个 id 获取到之前存储的数据。
其接受的 id 类型为 EntryRef,本质上是个 32 位的 id,在这个类型的定义中,默认情况下将前 10 位视为 buffer id,后 22 位为一个 buffer 内的 offset。DataStore 于是持有 2^10 即 1024 个 buffer,每个 buffer 可持有不同类型的数据。
当插入数据时
- 检查 free list 中是否有之前已释放的槽位;
- 检查当前插入的数据类型所指向的 active buffer 是否有空闲空间,否则切换到新的空闲的 buffer;
- 找到空闲的 buffer 后,定位至空闲的 offset,插入数据至此处;
- 此时 buffer id + offset 即构成了返回的 entry id。
当通过 entry id 获取数据时,即是线性地,将 entry id 分为 buffer id 和 offset 即可定位至相应的数据。
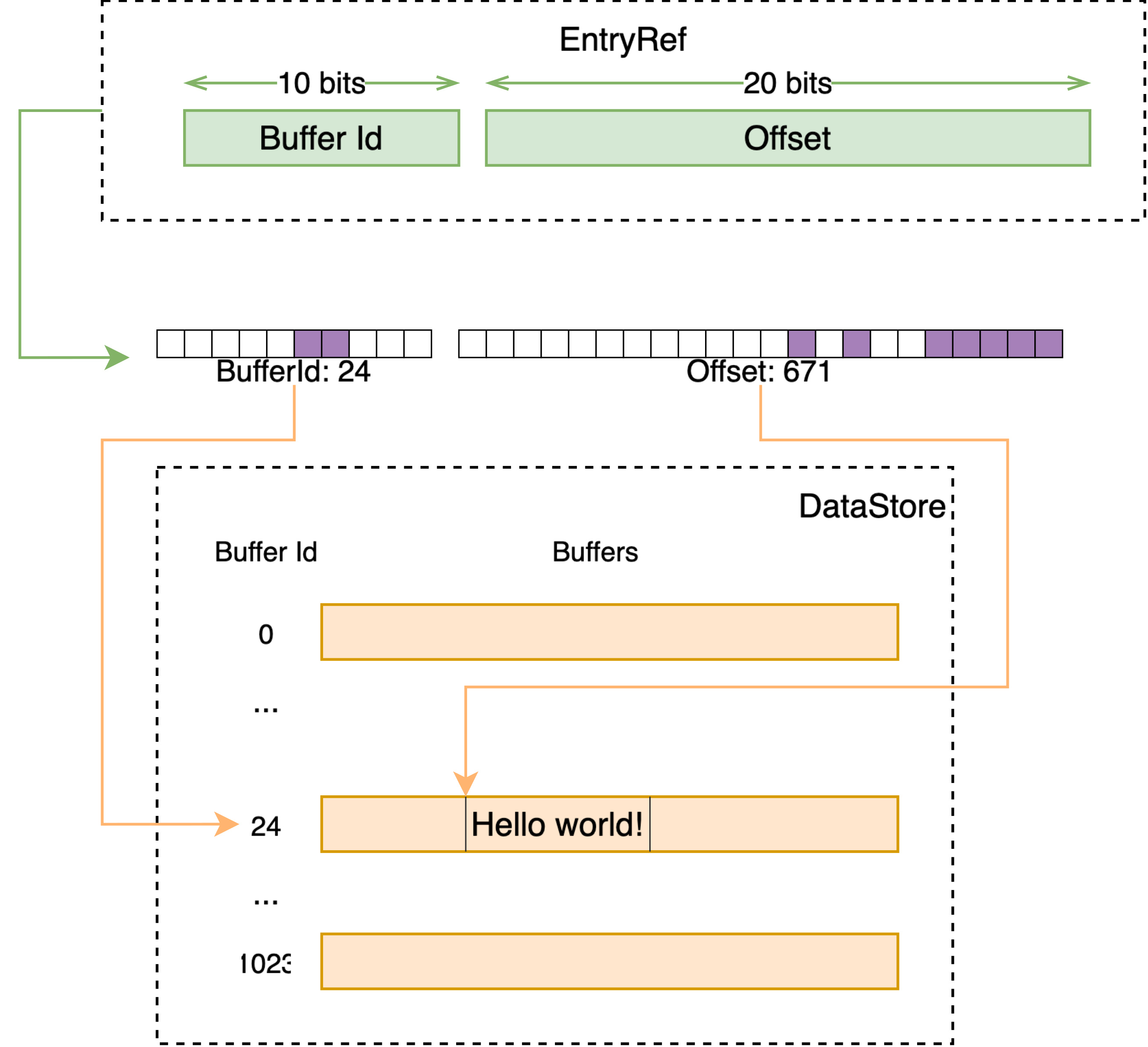
ArrayStore
ArrayStore 是基于 DataStore 上封装的支持单一类型、不同数组长度的数据结构。
EnumStore
EnumStore 在 DataStore 的基础上,用索引赋予了在这一系列数据(string, int 等 primary type)上进行快速查找的能力。
数据被直接地存储在 DataStore 中,而 EnumStoreDictionary 以这些存储的值为 key,value 中存储了其在 DataStore 中的 id 和对应的倒排表 id。
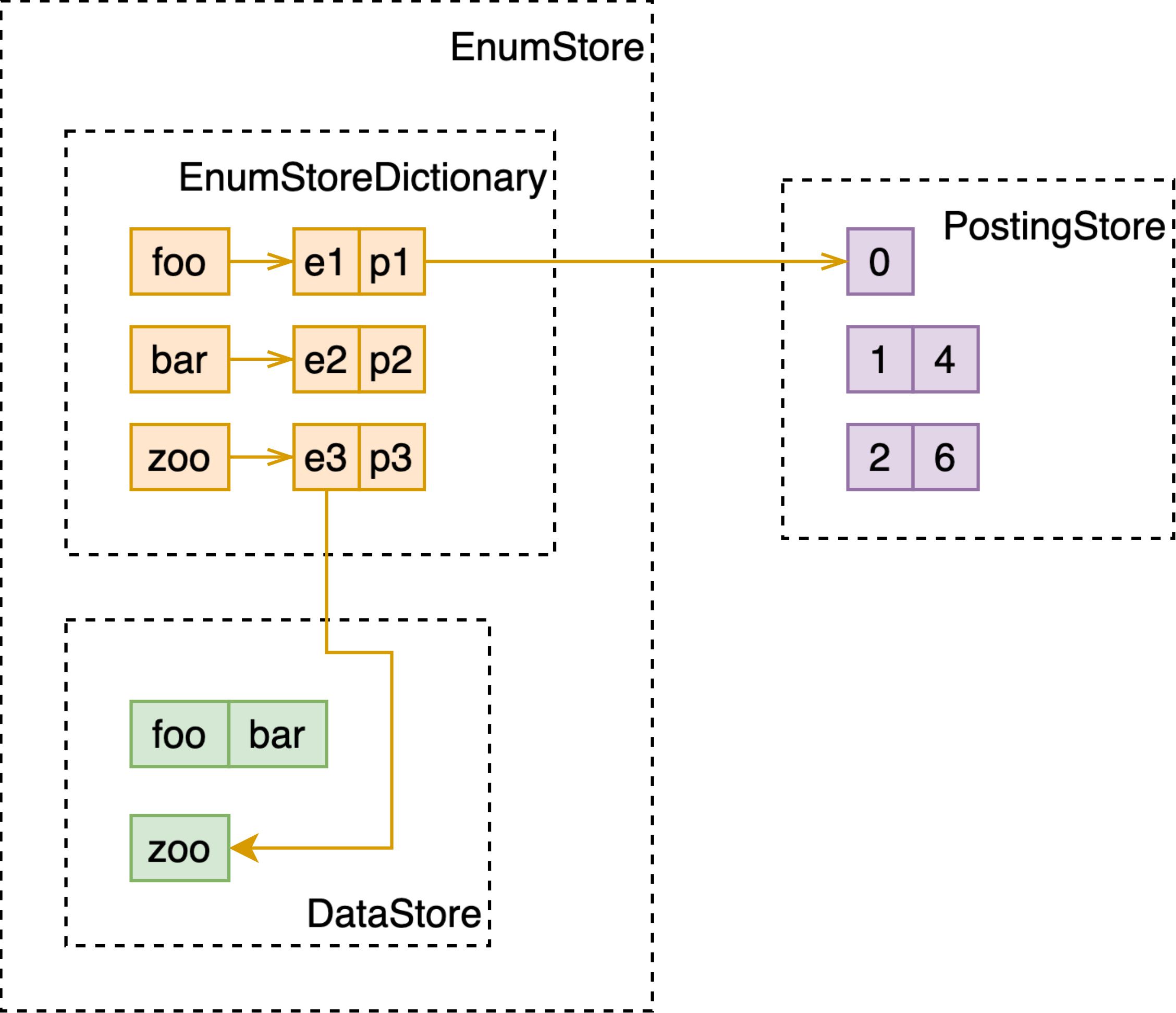
MultiValueMapping
EnumStore 只能支持单值字段的存储与检索,为了支持多值字段,如 array<int>、array<string>、weightedset<string>,MultiValueMapping 基于 RCUVector 和 ArrayStore 构建了 local docId 到多值字段值的映射。
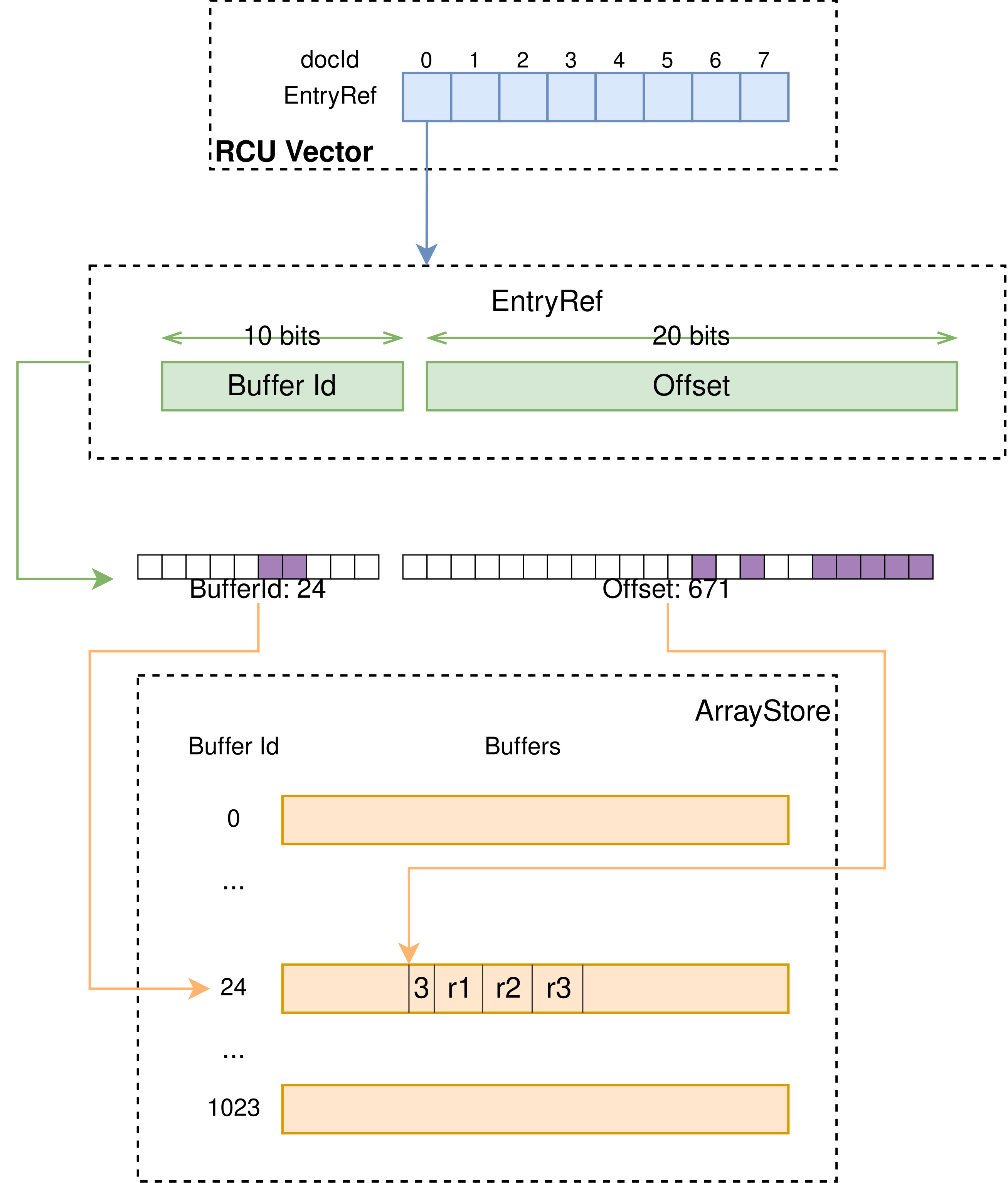
如上图所示,RCU Vector 以 docId 为序号,存储指向 ArrayStore 的 EntryRef。通过 EntryRef,能够获取到 ArrayStore 中存储的定长或变长的数组。
注意 ArrayStore 存储的数组,每个元素的长度是固定的,因此如果要存储多值 string 类型,要将字符串存储至额外的 EnumStore,这里只存储指向 EnumStore 的 EntryRef。
Sample App
简单了解,从用户视角来看,配置 vespa 需要:
- services.xml 最重要的集群配置,如下配置的含义是:
- 默认的无状态 container 配置;
- 集群内只有一种文档 / schema,shop_ads,其 TTL 为一天;
- 全局副本数 2;
- 配置两个组,每个组都有全量的文档,每个组各 3 个 node;
- 细节的配置参数如:
- 每个请求用 3 个线程;
- Indexing 只允许使用最多 40% 的 CPU;
- 磁盘文件的 mmap 方式使用 populate。
<services version="1.0">
<container id="default">
<search/>
<document-api/>
</container>
<content id="default">
<documents>
<document type="shop_ads" selection="shop_ads.mtime + 86400 > now()"/>
</documents>
<min-redundancy>2</min-redundancy>
<distribution partitions="1|*"/>
<group name="group0" distribution-key="0">
<node hostalias="node0" distribution-key="0"/>
<node hostalias="node1" distribution-key="1"/>
<node hostalias="node2" distribution-key="2"/>
</group>
<group name="group1" distribution-key="1">
<node hostalias="node3" distribution-key="3"/>
<node hostalias="node4" distribution-key="4"/>
<node hostalias="node5" distribution-key="5"/>
</group>
<engine>
<proton>
<tuning>
<searchnode>
<requestthreads>
<search>3</search>
</requestthreads>
<feeding>
<concurrency>0.4</concurrency>
</feeding>
<index>
<io>populate</io>
</index>
</searchnode>
</tuning>
</proton>
</engine>
</content>
</services>
- Schema shop_ads.sd,单个文档的配置,含义包括:
- 配置了若干字段,其中:
- 除 primitive 类型外,支持 array,map,向量;
attribute: fast-search构建索引;indexing: index分词、构建倒排索引;- 支持 HNSW 参数;
- 配置了 rank-profile,含义等同于 monad rank-profile:
- 第一阶段计算向量分;
- 第二阶段取第一阶段的 top 2000,加入 bm25 分数;
- 配置了 document-summary,预定义请求返回的字段。
- 配置了若干字段,其中:
schema shop_ads {
document {
field shop_id type string {
indexing: attribute | summary
}
field item_id type string {
indexing: attribute | summary
}
field mtime type string {
indexing: attribute | summary
}
field price type int {
indexing: attribute | summary
attribute: fast-search
}
field title type string {
indexing: attribute | index | summary
}
field keywords type array<string> {
indexing: attribute | summary
attribute: fast-search
}
struct ItemInfo {
field price type int {}
field weight type int {}
field visible type bool {}
}
field broad_item_info type map<string, ItemInfo> {
indexing: summary
summary: matched-elements-only
struct-field key {
indexing: attribute
attribute: fast-search
}
struct-field value.visible {
indexing: attribute
attribute: fast-search
}
}
field ctr_vec_v1 type tensor<float>(x[64]) {
indexing: attribute | index | summary
attribute {
distance-metric: dotproduct
}
index {
hnsw {
max-links-per-node: 64
neighbors-to-explore-at-insert: 512
}
}
}
}
rank-profile ctr_v1 {
first-phase {
expression: "closeness(field, ctr_vec_v1)"
}
}
rank-profile v1 inherits ctr_v1 {
second-phase {
expression: "firstPhase + bm25(title)"
rerank-count: 2000
}
}
document-summary simple {
summary shop_id {}
summary item_id {}
summary mtime {}
summary title {}
omit-summary-features: true
}
document-summary v1 inherits simple {
summary keywords {}
summary broad_item_info {}
}
}
YQL 语法类似于 SQL;
{
"yql": '''select * from shop_ads
where title contains phone
and keywords matches iPhone
and broad_item_info.key matches iPhone
'''
"ranking.profile": "v1",
"summary": "simple"
}
或者在之前的工作中,改造为了易于从 ES 迁移的模式:
{
"query": {
"bool": {
"filter": [ // 不参与分数计算
{
"term": {
"field": "title",
"value": "phone"
}
}
],
"should": [
{
"term": {
"field": "title",
"value": "iPhone"
}
},
{
"term": {
"field": "broad_item_info.key",
"value": "iPhone"
}
}
]
}
},
"ranking": {
"profile": "v1"
},
"presentation": {
"summary": "simple"
}
}